Linux and EM64T; Intel's 64-bit Suggestion
by Kristopher Kubicki on August 9, 2004 12:05 AM EST- Posted in
- Linux
Synthetic Benchmarks
Our Nocona server was setup in a remote location with little access, so we had limited time to run as many real world benchmarks as we are typically accustomed to. Fortunately, there are multitudes of synthetic benchmarks that we can use to deduce information quickly and constructively.Sieve of Atkin (primegen)
Primegen is an older, but still useful library for generating prime numbers in order using the Sieve of Atkin. We compiled the Bernstein implementation by simply running "make". We ran the program as so:# time ./primes 1 100000000000 > /dev/null
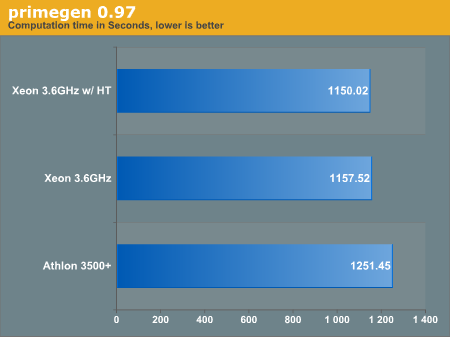
We found the benchmark to be extremely reliable and we replicated our figures continually with less than 1% difference.
Super Pi
We ran the Linux compilation of Super Pi 2.0, which is a closed source application. We are not aware of which optimizations are compiled with the program and we are prohibited from redistributing the binaries. Please download the latest binaries from ftp://pi.super-computing.org/Linux. We ran the command:# ./super_pi 20
Below is the program's output of calculation time in number of seconds.
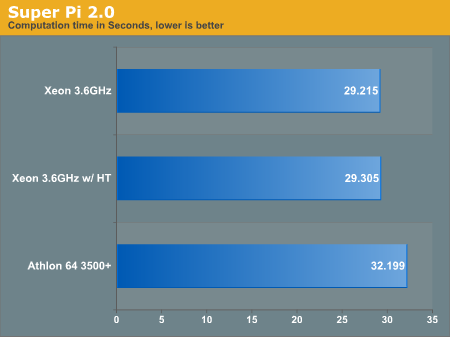
After re-running the program several times, our benchmarks never deviated outside of 1%. In a mathematical operation-only situation, the Intel processor has outpaced the AMD offering twice now.








275 Comments
View All Comments
ss284 - Monday, August 9, 2004 - link
Its funny how all the illiterate morons who couldnt read, shut up after it was made clear that the xeon 3.6 is using the same core as the prescott 3.6 em64t.Not to mention that if anything, a non registered enthusiast board with standard pc 3200 memory at cas 2 will perform better than the tumwater setup.
Otherwise, there are some pretty serious errors in the article, all of which have been mentioned. The most important is probably the lack of 32-bit comparisons and some discrepancies in the benchmarks. You might also want to make it very obvious that performance on a prescott 3.6 em64t will be similar if not faster than your current numbers so the more morons like the ones in this thread dont start complaining of how you should be comparing this to an opteron.
-Steve
Xspringe - Monday, August 9, 2004 - link
Jup, the TSCP seem to be flawed as well, this guy also got different results ( http://f11.parsimony.net/forum16635/messages/69533... ) then those provided in this article.The fact that a quick evaluation of the results already yields two significant errors as well as various other peculiarities makes me question the validity entire article.
I hope that Anandtech will take the time to redo this article in a proper way, with a reasonable benchmark set, 32 vs 64 bit comparisons and comparable processors.
I also strongly suggest that you add a footnote to the article to clarify any issues that have been mentioned in the comment section.
Either that or pull the article in it's entirity until it has been improved to the standards which we normally can expect from Anandtech.
dougSF30 - Monday, August 9, 2004 - link
These results are WRONG.3500+ vs. Opteron 150 is only a minor issue, compared to the other mistakes.
The TSCP makefile is broken, and does not apply -O2 optimization. With -O2, you'll score about 300K n/s.
As mentioned, primegen spends nearly all its time in putchar. Just edit primes.c and comment out the putchar() loop. Then edit conf-cc and bump the optimization to -O2. Re-run on both systems.
ubench is known to be broken. the AMD64 results are implausible.
You copied the result for Test-Select over incorrectly, choosing the 32b result instead of the 64b result. The 3500+ wins that one, too.
I suspect you have similar issues with the compilation and optimization in "John the Ripper", but I have not investigated that one yet.
gzip is apparently 32b by default, so that test may be not what you think it is.
super_pi is also probably 32bit, and who knows what it was optimized for???
This whole review is filled with errors. Get someone to help you compile and optimize software.
Needless to say, the conclusion about "math performance" is not warranted.
This should be pulled down until the results have been re-run correctly.
mrdoubleb - Monday, August 9, 2004 - link
My previous comment (#91) was in repronse to johnsonx's reaction (#69).mrdoubleb - Monday, August 9, 2004 - link
Just for your information (since you've referred to my comment).What most of us have been complaining about is that this benchmark should have been set up more like this:
http://www.tecchannel.de/hardware/1441/index.html
They put 2 Nocona 3.6 processors against a pair of Opteron 250s. Both are the top two way x86-64 server processors of the 2 big rivals costing exactly the same. These benchmarks are detailed, appropriate (they use the applications these processors will be used for) and even use SSE3 for Nocona. Of course the Nocona is excellent compared to its predecssor, and it turns out that each processor has its strengths and weaknesses. Nobody complained that AMD doesn't win ALL the benchmarks.
They should have done something like this benchmark only with "linux 64" instead of "windows xp 32".
dali71 - Monday, August 9, 2004 - link
The message is clear...Kristopher has failed!(Sorry, had to be said for old times sake;) )
ten9 - Monday, August 9, 2004 - link
The makefile used in TSCP on the A64 is totally screwed up!Read this comment on aces:
http://www.aceshardware.com/forum?read=115093868
They get: Nodes per second: 281583 (Score: 1.158)
on a non-overclocked AXP 2500+ on a single channel Via board
ashay - Monday, August 9, 2004 - link
Any Truth in this ? :by kent.dickey (685796) on Monday August 09, @01:28PM (#9921562)
The "primegen" program listed where the Xeon beats the Athlon slightly does not do any floating point.
I looked at the code and played with it a little (I got it from http://cr.yp.to/primegen.html [cr.yp.to] and it seems the benchmark is mostly limited by the implementation of putchar().
My system was an dual AMD Opteron 1.8GHz running Win XP pro with Cygwin. I modified the benchmark to not use putchar() but instead just write the characters to a 1MB buffer, and it got 16 times faster! To be specific, "primes 1 100000000 > file" went from 24.2 seconds to 1.497. Note that it's generating 51MB of output for primes under 100 million. I didn't bother running it for the 100 billion max, but would expect it to be around 50GB.
This is a very poor benchmark since it's just measuring your stdc implementation of putchar and your system's ability to sink data to /dev/null, not anything useful.
Zebo - Monday, August 9, 2004 - link
With thier server implications where are the server benches?..you have sql.. which A64 trouces as expected in 64bit..Where are Samba File Transfers which simulates client access to a server? Where are the apache benches which is world’s most popular webserving software?
Even so, with the limited benches we have the Athlon wins or ties every single 64bit non-synthetic benchmark. Audio Encoding, POV-RAY, GZip and 64 bit MySql. Only when the synthetics are thrown in does Intel dominate...wonder why.
RZaakir - Monday, August 9, 2004 - link
While I think that it's interesting that the upcoming PIV is supposed to be the "exact" same as the Nocoma chip (if so then why differentiate?), I don't think that this review is quite the travesty that it's being made out to be. I do think that it is incomplete given the fact that we aren't really being shown how effective EMT64 is though.Hopefully the next review will address all of the controversy that has ensued.