Linux Shootout: Opteron 150 vs. Xeon 3.6 Nocona
by Kristopher Kubicki on August 12, 2004 2:35 PM EST- Posted in
- Linux
Opstone
Since our use of Ubench in the previous article clearly infuriated many people, we are going to kick that benchmark to the side for the time being until we can decide a better way to implement it.
In the meantime, a reader suggested we give Blue Sail Software's Opstone benchmarks a try. In this portion of the review, we will use their precompiled optimized binaries of the Scalar Product (SP) and Sparce Scalar Product (SSP) benchmark. The SP benchmark is explained by the author:
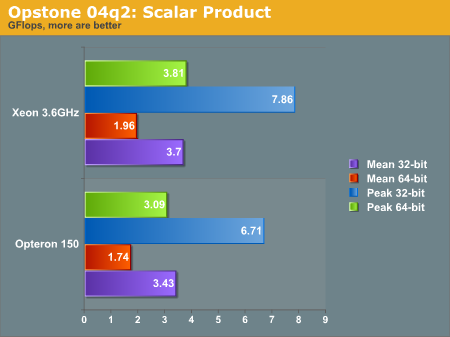
"The 'SP' benchmark calculates the scalar product (dot product) of 2 vectors ranging in size from 16 elements to 1048576 elements for both single and double-precision floats. Although the Gflops/sec. for every vector length is recorded (in the resulting output log file), the average of all these values is reported. This benchmark is indicative of the performance of many raw floating-point data processing apps (movie format conversion, MP3 extraction, etc.)"
Note that we ran the P4 optimized binaries on the Nocona, which did not provide x86-64 enhancements. Running the AMD64 binaries on the Xeon yielded poor results. The P4 Opstone binaries are the only 32-bit binaries used in this analysis.
Below is the SSP benchmark, as explained by the author:
"The 'ssp' benchmark also calculates the scalar product of 2 vectors, except that these vectors are sparsely populated (only the non-zero value elements are stored) ranging from a 'loading factor' (non-zero/zero elements) of 0.000001 to 0.01 for both single and double-precision floats. Since the data is not contiguous in memory, the performance is much lower than regular 'sp' and is measured in Mflops/sec. There is not much difference in performance between different loading factors as this benchmark really challenges the ability of the processor to perform short bursts of calculations coupled with lots of conditional testing. It is this reason that the P4 with its longer pipeline does not generally perform as well as the Athlon64. This benchmark is indicative of the performance of many 3D games as the processing is similar (short bursts of calculations with numerous conditional testing)"
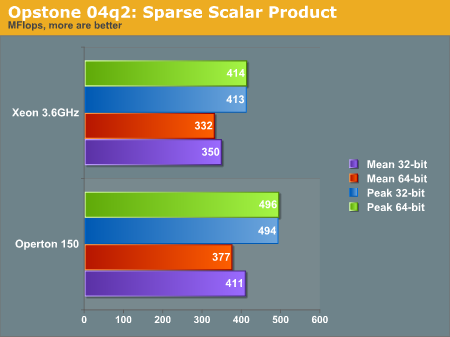
There is a general distrust of synthetic benchmarks, so take this portion of the analysis only with a grain of salt. We see a tale of two processors in these graphs; generally the Xeon performs better in the raw operation SP benchmark, while the Opteron performs better in the condition testing SSP benchmark. We would be lead to believe the Intel processor does content integer content creation better than the Opteron, and visa versa with floating point applications. However as we see in the rest of the review, this is not always the case.








92 Comments
View All Comments
adiposity - Thursday, August 12, 2004 - link
> From looking at the graphs, it becomes easy to> see why JTR makes a difficult program to use as
> a benchmark. Had we left the default -O2
> compilation, Blowfish hashing would have been
> faster on the Xeon processor than the Opteron.
> However, as soon as we use -O3, the Opteron
> outperforms the Xeon processor.
Um, no it doesn't. The opteron continues to lose, even with the -O3 optimization. In fact, -O3 doesn't seem to help either significantly in any of the JTR benchmarks.
-O2: Xeon wins 481 to 419
-O3: Xeon wins 478 to 420
Of course, Opteron wins the rest, and -O3 doesn't seem to matter there, either.
-Dan
Dranzerk - Thursday, August 12, 2004 - link
Kris glad you included Crafty chess program into review. If you want to address anything dealing with the Program (like test wise) you can contact Dr. Robert Hyatt directly through ICC (Internet chess club, free to use if you log on as a Guest) he is online there as the name Hyatt.He is very easy to talk to about crafty if you need help.
douglar - Thursday, August 12, 2004 - link
The one thing that I really see in these benchmarks is how much Intel is suffering when they are trying to run AMD64 optimized code. Normally intel makes the spec for new instructions before AMD impliments, the compiler writers and software coders take advantage of Intel's peculiaries and then AMD has to build the functionality with the same peculiaries as the intel implimentation if they want to compete. Look at most SSE2 benchmarks. I think AMD is at a disadvantage having had to back fit the instructions using the existing CPU op units.This time it looks like intel is getting a taste of their own bitter medicine, trying to make 32bit integer units look and perform like 64bit units to the outside world, if the rumors about intel's 64bit implimentation are true. Now it will be interesting to see if compiler writers and software coders will (or are able to) go back to the drawing board and make this round of intel chips perform up to the strong initial AMD 64 bit performance baseline.
I'm guessing that there will be a 64 bit performance gap (larger than the 32 bit gap) until intel respins the silicon a couple times. I look at this round of 64bit intel chips as like a em64sx, in reference to the 386sx, even though the 386sx was 32 internally an 16 externally, kind of the opposite of having 64bit registers and 32bit ops units, but perhaps still an appropriate analogy.
Macro2 - Thursday, August 12, 2004 - link
Kris,I have to hand it to you, you took a lickin' and kept on tickin'. I realize it's pathetic that in order to do a review you have to literally dissect every benchmark for "fuzzy" code but that's the way it is. Got to do the homework and if it's out of the realm om your expertise yoou have to ask other. Remember, benchmarks are for liars.
That said, you'll probably turn out to be the best comparitive benchmark reviewer on the internet.
Mac
mrdoubleb - Thursday, August 12, 2004 - link
Good job, Kris!1, Now I'd just like to point out, that it's not like nobody is complaining now becouse this time AMD wins. This time around the processor choice was ok and, as much as I see from the opinions of readers who are much better informed in the server/linux world than me, the benchmark choice/execution was great, too.
2, I know you're off to your vacation now (by the way, have a good time!), bat later it would be interesting if you managed to do a 2 and/or 4 processor setup with Noconas and opteron 250/850s as well. As far as i know, Opteron's biggest advantage was its excellent scalability. Opteron's advantage used to grow immensly. Does this change with the new Noconas?
3, I saw this at another HW site: on the final page of their reviews they have a chart where they list all the benchmarks once more and show with a percentage number how faster/slower a processor is compare to its rival. E.g. you take the nocona as 100% (or zero) and list for every benchmark how faster/slower Opteron was. (Say, +25% or -37%).
4, As for pos #36 by kaoman. I think that if they had compared 2 desktop processors, than we wouldn't have seen any of these benchmarks, save for Lame. We would have seen office, gaming, AV, and rendering benchmarks. And about the price: let's wait for it, shall we?! By the time Prescott 3.6F is available, 90nm A64 is out, which might also be tweaked, if the rumor mill is right, and it will also be cheaper for AMD to produce, so it might be cheaper for us as well.
Have great holiday, Kris!
kresek - Thursday, August 12, 2004 - link
Thanks for the SSL benches.Especially useful are 1024+ bits RSA/DSA sign/verify figures (at the bottom), digests: MD5 or SHA-1, and popular ciphers, like RC4, blowfish. Take 1024 bytes or bigger blocks, and you have valuable, easy to visualize comparison information.
Pjotr - Thursday, August 12, 2004 - link
""Now will all of you A-Holes get off KrizK's & AT editorial staff's back!!"HAHHAHAHAHAHA I'm laughing my ass off.
Great Job getting in the first post, and a good first post at that."
I don't think it was a good post. Calling people with valid views, that even the author acknowledged, "A-holes" is just blunt and irrelevant.
skiboysteve - Thursday, August 12, 2004 - link
great review, glad to see you take the readers to heart.Pjotr - Thursday, August 12, 2004 - link
Great job, Kris, and thanks to Super Micro! It's good to see when people don't just hide, but both listen and respond. I was ready to remove Anand from my bookmarks like I did with Tom's years ago, but it's staying now.Soultrap - Thursday, August 12, 2004 - link
Kris,Awsome! You took it like a man, and I think that all of us learned from your hard work including the errors in it. I feel that you did your abosolute best to accomodate & listen to your readers, correct your errors, and produce an unbiased evaluation.
There is nothing anybody can do about their mistakes except do their best to correct them and learn from them.
After reading these posts to your new article I am sure that you blood preasure has dropped greatly. Harsh (un)constructive criticism can be very difficult to take.
Good work!