ARM Unveils Next Generation Bifrost GPU Architecture & Mali-G71: The New High-End Mali
by Ryan Smith on May 30, 2016 7:00 AM ESTThe Bifrost Core: Decoupled
Finally moving up to the 500ft view, we have the logical design of a single Bifrost core. Augmenting the changes we’ve discussed so far at the quad/execution engine level, ARM has made a number of changes to how the rest of the architecture works, and how all of this fits together as a whole.
First and foremost, a single Bifrost core contains 3 quad execution engines. This means that a single core is at any time executing up to 12 FMAs, spread over the aforementioned 3 quads. These quads are in turn fed by the core’s thread management frontend (now called a Quad Manager), which combined with the other frontends issues work to all of the functional units throughout the core.
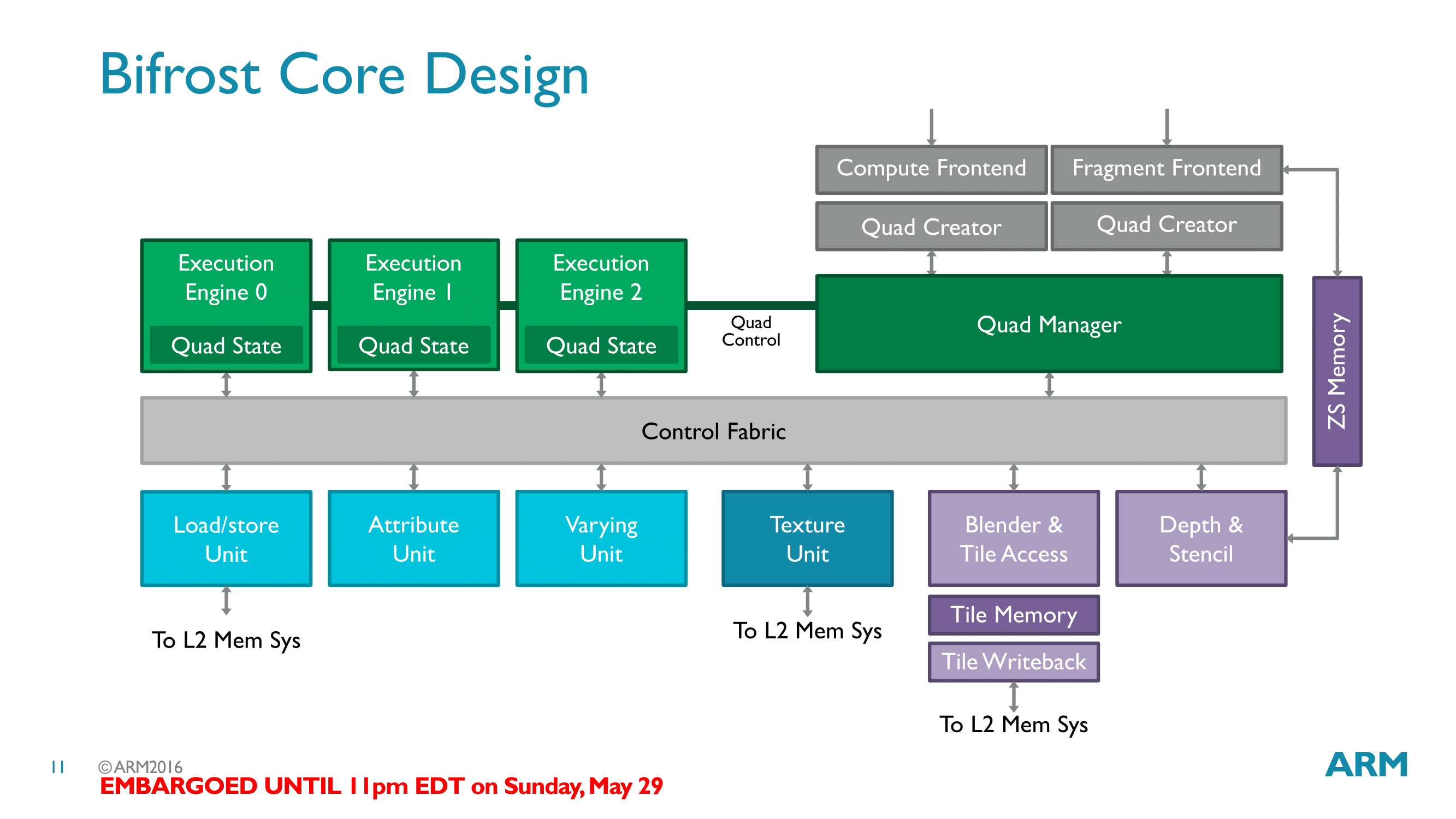
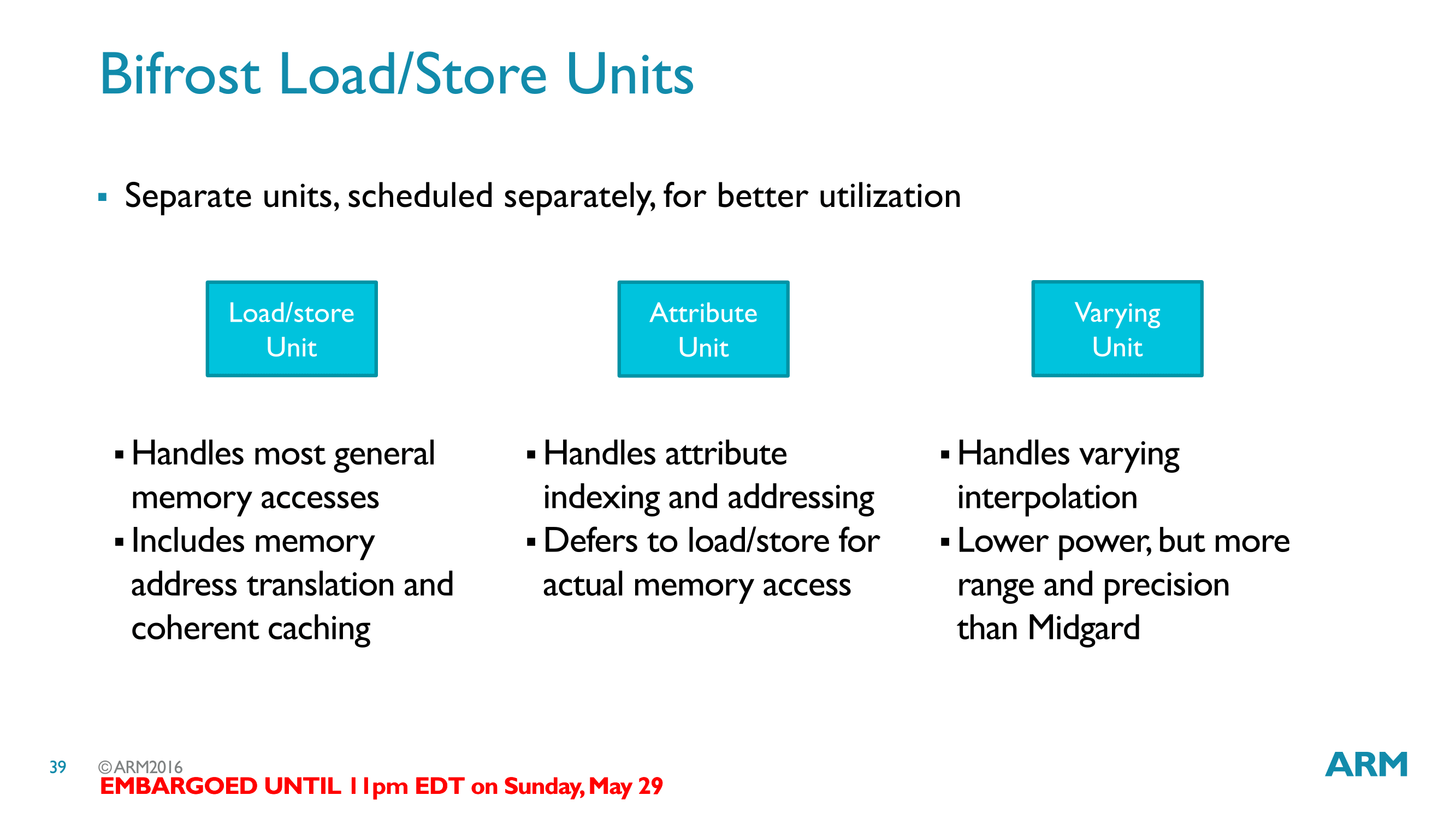
As we’ve now seen the quad execution engines, insightful readers might have noticed that the execution engines are surprisingly sparse. They contain ALUs, register files, and little else. In most other architectures – including Midgard – there are more functional units organized within the execution engines, and this is not the case for Bifrost. Instead the load/store unit, texture unit, and other units have been evicted from the execution engines and placed as separate units along the control fabric.
Along with the shift from ILP to TLP, this is one of the more significant changes in Bifrost as compared to Midgard. Not unlike the TLP shift then, much of this change is driven by resource utilization. These units aren’t used as frequently as the ALUs, and this is especially the case as shader programs grow in length. As a result rather than placing this hardware within the execution engines and likely having it underutilized, ARM has moved them to separate units that are shared by the whole core.
The one risk here is now that there’s contention for these resources, but in practice it should not be much of an issue. Comparatively speaking, this is relatively similar to NVIDIA’s SMs, where multiple blocks of ALUs share load/store and texture units. Meanwhile this should also simplify core design a bit; only a handful of units have L2 cache data paths, and all of those units are now outside of execution engines.
Overall these separated units are not significantly different from their Midgard counterparts, and the big change here is merely their divorce from the execution engines. The texture unit, for example, still offers the same basic feature sets and throughput as Midgard’s, according to ARM.
Meanwhile something that has seen a significant overhaul compared to Midgard is ARM’s geometry subsystem. Bifrost still uses hierarchical tiling to bin geometry into tiles to work on it. However ARM has gone through quite a bit of effort here to reduce the memory usage of the tiler, as high resolution screens and higher geometry complexity was pushing up the memory usage of the tiler, and ultimately hurting performance and power efficiency.
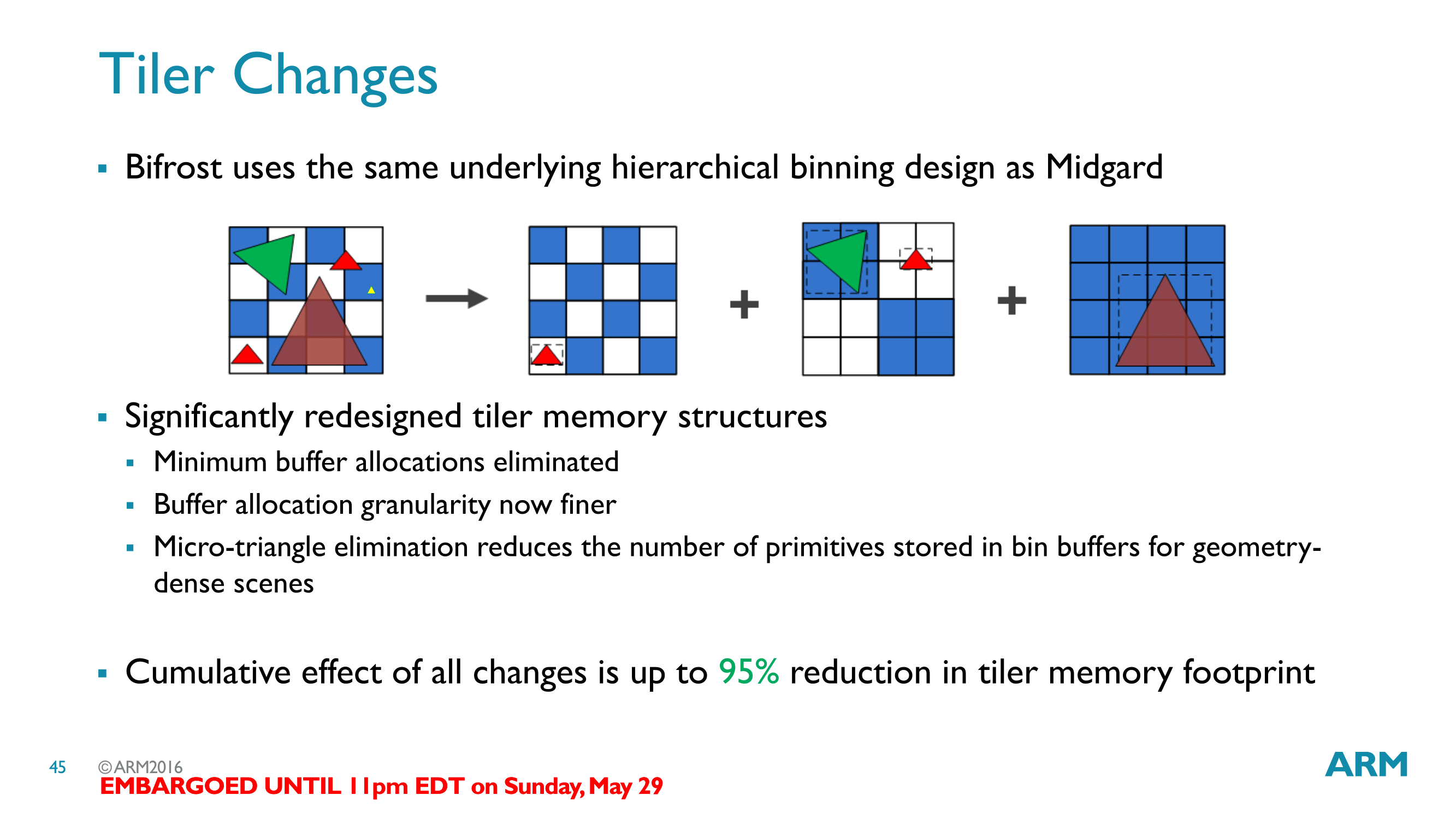
Bifrost implements a much finer grained memory allocation system, one that also does away entirely with minimum allocation requirements. This keeps memory consumption down by reducing the amount of overhead from otherwise oversized buffers.
But perhaps more significant is that ARM has implemented a micro-triangle discard accelerator into Bifrost. By eliminating sub-pixel triangles that can’t be seen early on, ARM no longer needs to store those tringles in the tiler, further reducing memory needs. Overall, ARM is reporting that Bifrost’s tiler changes are reducing tiler memory consumption by up to 95%.
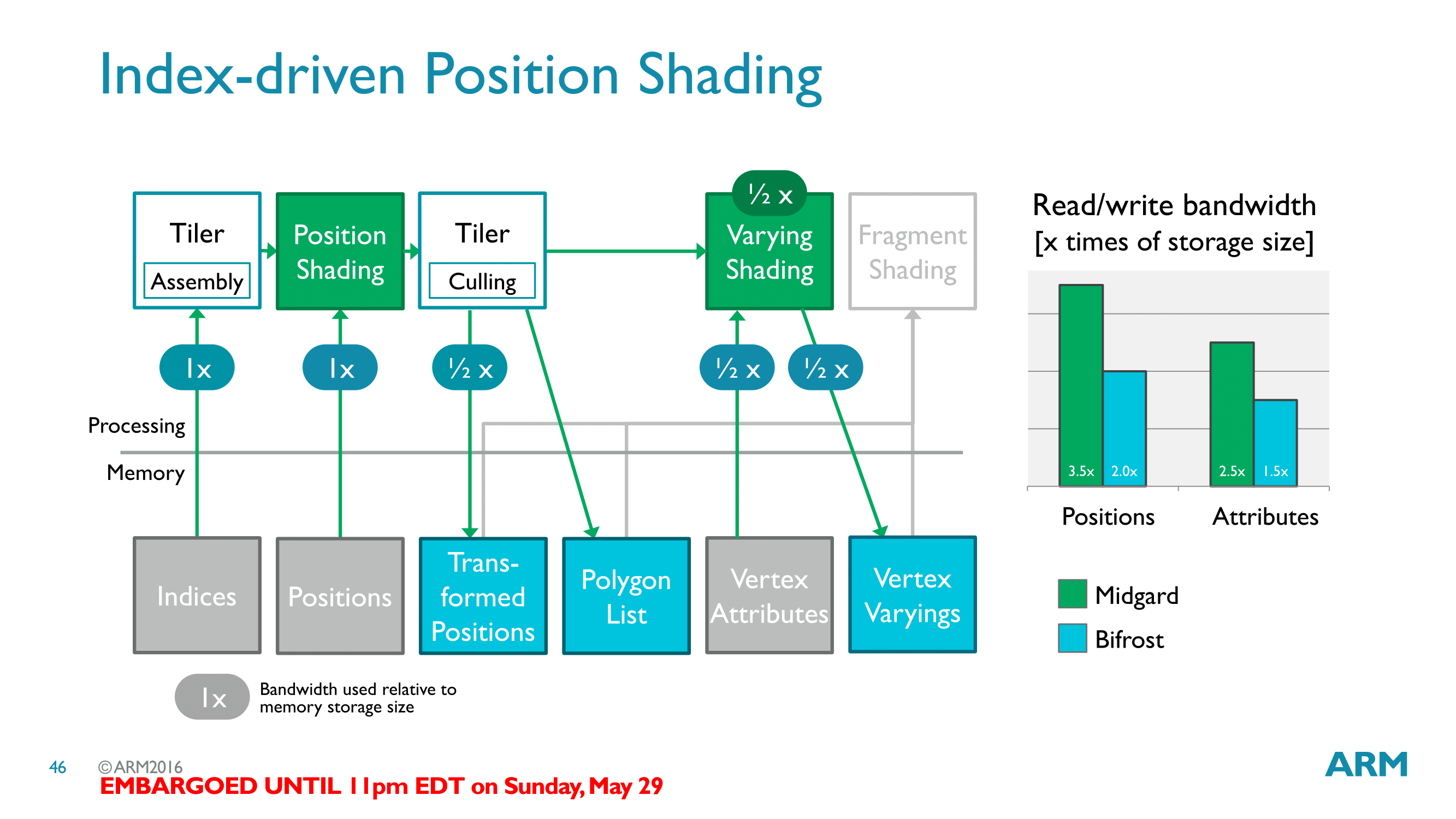
Along similar lines, ARM has also targeted vertex shading memory consumption for optimization. New to Bifrost is a feature ARM is calling Index-Driven Position Shading, which takes advantage of some of the aforementioned tiler changes to reduce the amount of memory bandwidth consumed there. ARM’s estimates put the total bandwidth savings for position shading at around 40%, given that only certain steps of the process can be optimized.
Finally, at the opposite end of the rendering pipeline we have Bifrost’s ROPs, or as ARM labels them, the blending unit and the depth & stencil unit. While these units take a similar direction as the texture unit – there are no major overhauls here – ARM has confirmed that Bifrost’s blending unit does offer some new functionality not found in Midgard’s. Bifrost’s blender can now blend FP16 targets, whereas Midgard was limited to integer targets. The inclusion of floating point blends not only saves ARM a conversion – Midgard would have to covert FP16s to integer RGBA – but the native FP16 blend means that precision/quality should be improved as well.
FP16 blends have a throughput of 1 pixel/clock, just like integer blends, so these are full speed. On that note, Bifrost’s ROP hardware does scale with the core count, so virtually every aspect of the architecture will scale up with larger configurations. Given what Mali-G71 can scale to, this means that the current Bifrost implementation can go up to 32px/clock.








57 Comments
View All Comments
Ranger1065 - Monday, May 30, 2016 - link
Interesting but not quite the GPU review the faithfull are awaiting...hope springs eternal.Shadow7037932 - Monday, May 30, 2016 - link
This is more interesting than a GTX 1070/1080 review imo. We more or less know what the nVidia cards are capable of. This ARM GPU design will be relevant for the next 2-3 years.Alexey291 - Monday, May 30, 2016 - link
Well yeah, ofc it's not interesting anymore because by the time their reviews hit whatever it is they are reviewing is a known quantity. 1080 in this case is a perfect example.name99 - Tuesday, May 31, 2016 - link
Oh give it a rest! Your whining about the 1080 is growing tiresome.SpartanJet - Monday, May 30, 2016 - link
Relevant for what? Phone GPU's are fine as is. For mobile gaming? Its all cash shop garbage. For productivity? ADroid and iOS pale in comparison to a real OS like Windows 10.I find the Nvidia much more interesting.
name99 - Tuesday, May 31, 2016 - link
"Phone GPUs are fine as is."And there, ladies and gentlemen, is the "640K is enough for anyone" of our times...
Truly strong the vision is, in this one.
imaheadcase - Tuesday, May 31, 2016 - link
He is not wrong though. A faster GPU on one offers nothing for people as of right now. If you look at the mobile apps that are used, not a single one would even come close to using what they use now..and phones are at max quality for the screen size they use.The only way phones can improve now that users would notice is storage/CPU/and better app quality in general which is terrible.
shadarlo - Tuesday, May 31, 2016 - link
You realize that GPU's are used for things beyond prettying up a screen right?Lets just stop advancing mobile GPU's because in the future we will never use anything more advanced that needs more power or less power usage... *eye roll*
ribzy - Monday, November 21, 2016 - link
I think what he's trying to say is that the content is not available or sufficient right now to really justify the cost. Let's say you built a car but don't have the fuel that's needed to power it. Or what about those that got a 4K TV early and now are stuck with something that doesn't have HDR and that runs old, not updateable TV software. I understand his concern.mr_tawan - Thursday, June 2, 2016 - link
Well as the phone's and tablet's resolution is going ridiculously higher and higher everyday, having strong GPU is a must. It's not all about gaming, it affects day-to-day use as well. Everything on displays now on every OS nowadays are hardware-accelerated. And the current mobile GPU are under-power comparing to the task it's given (eg. driving 2K displays at 60fps).