CEVA Launches Fifth-Generation Machine Learning Image and Vision DSP Solution: CEVA-XM6
by Ian Cutress on September 27, 2016 9:30 AM EST- Posted in
- SoCs
- DSPs
- Machine Learning
- Neural Networks
- CEVA
- XM6
- GoogleNet
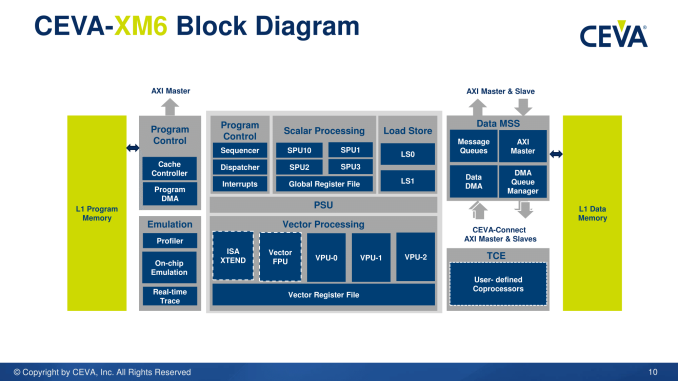
Deep learning, neural networks and image/vision processing is already a large field, however many of the applications that rely on it are still in their infancy. Automotive is the prime example that uses all of these areas, and solutions to the automotive 'problem' are require significant understanding and development in both hardware and software - the ability to process data with high accuracy in real-time opens up a number of doors for other machine learning codes, and all that comes afterwards is cost and power. The CEVA-XM4 DSP was aimed at being the first programmable DSP to support deep learning, and the new XM6 IP (along with the software ecosystem) is being launched today under the heading of stronger efficiency, compute, and new patents regarding power saving features.
Playing the IP Game
When CEVA launched the XM4 DSP, with the ability to infer pre-trained algorithms in fixed-point math to a similar (~1%) accuracy as the full algorithms, it won a number of awards from analysts in the field, claiming high performance and power efficiency over competing solutions and the initial progression for a software framework. The IP announcement was back in Q1 2015, with licensees coming on board over the next year and the first production silicon using the IP rolling off the line this year. Since then, CEVA has announced its CDNN2 platform, a one-button compilation tool for trained networks to be converted into suitable code for CEVA's XM IPs. The new XM6 integrates the previous XM4 features, with improved configurations, access to hardware accelerators, new hardware accelerators, and still retains compatibility with the CDNN2 platform such that code suitable for XM4 can be run on XM6 with improved performance.
CEVA is in the IP business, like ARM, and works with semiconductor licensees that then sell to OEMs. This typically results in a long time-to-market, especially when industries such as security and automotive are moving at a rapid pace. CEVA is promoting the XM6 as a scalable, programmable DSP that can scale across markets with a single code base, while also using additional features to improve power, cost and performance.

The announcement today covers the new XM6 DSP, CEVA's new set of imaging and vision software libraries, a set of new hardware accelerators and integration into the CDNN2 ecosystem. CDNN2 is a one-button compilation tool, detecting convolution and applying the best methodology for data transfer over the logic blocks and accelerators.
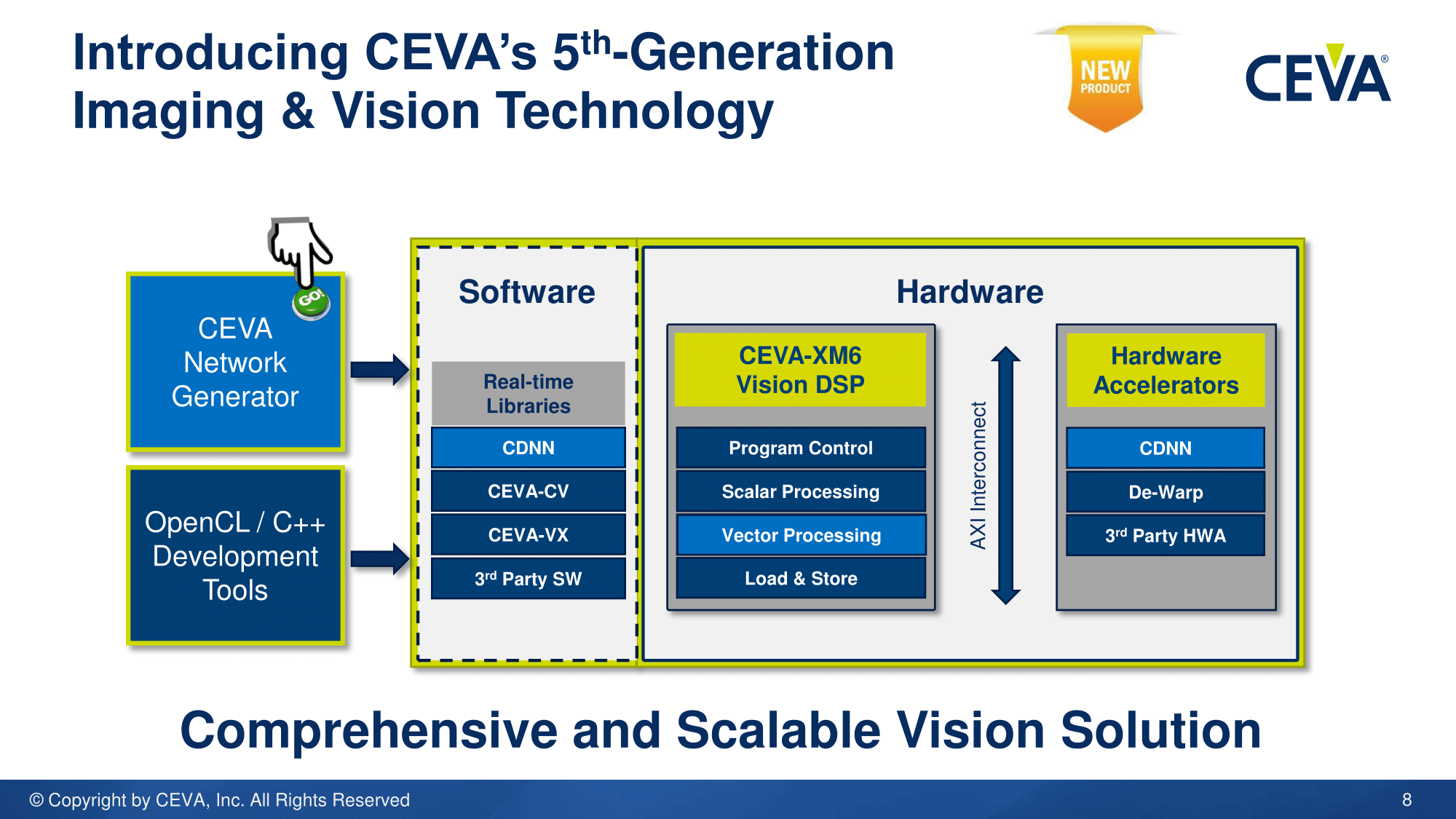
XM6 will support OpenCL and C++ development tools, and the software elements include CEVA's computer vision, neural network and vision processing libraries with third-party tools as well. The hardware implements an AXI interconnect for the processing parts of the standard XM6 core to interact with the accelerators and memory. Along with the XM6 IP, there are hardware accelerators for convolution (CDNN assistance) allowing lower power fixed function hardware to cope with difficult parts of neural network systems such as GoogleNet, De-Warp for adjusting images taken on fish-eye or distorted lenses (once the distortion of an image is known, the math for the transform is fixed-function friendly), as well as other third party hardware accelerators.
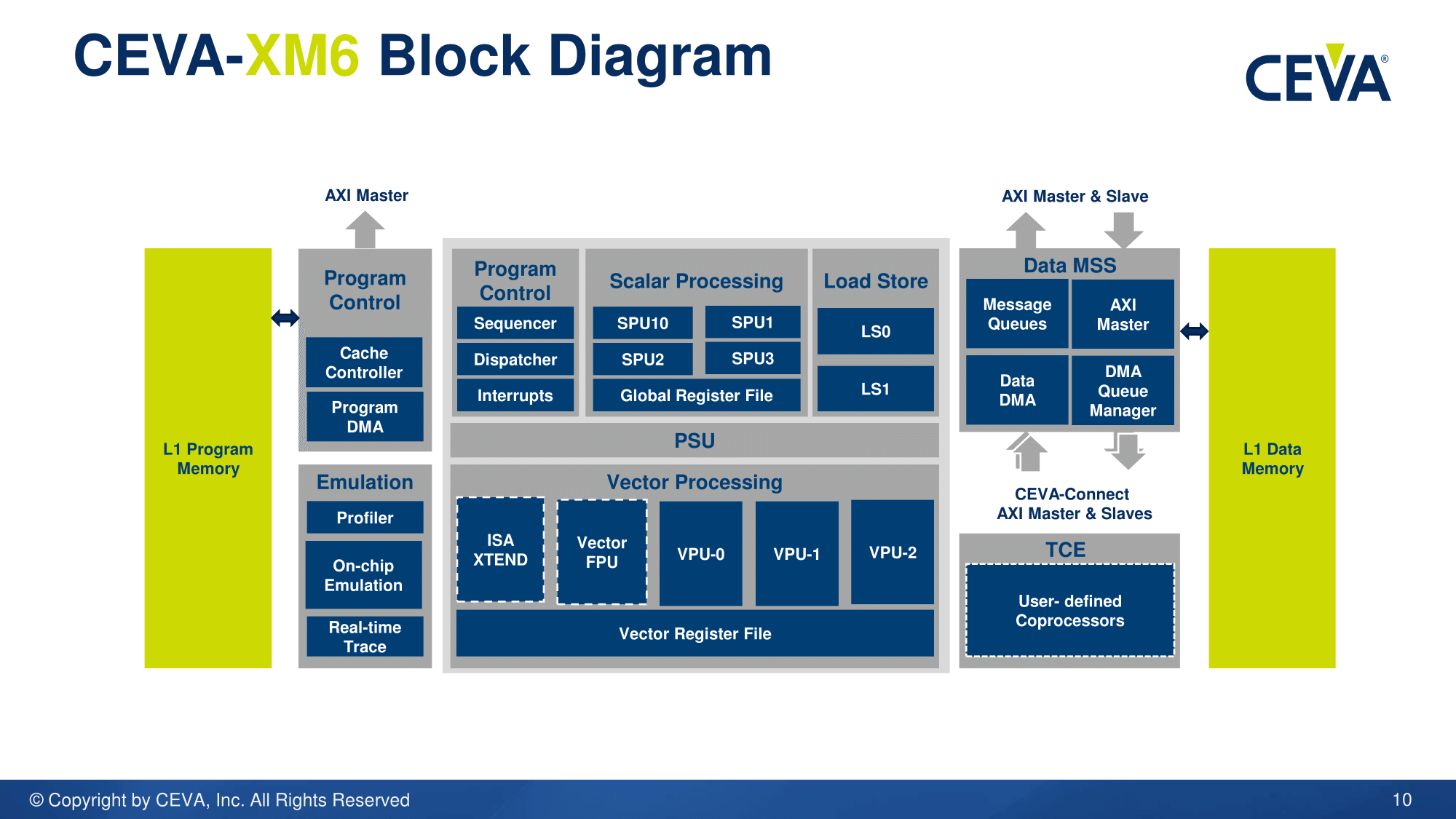
The XM6 promotes two new specific hardware features that will aid the majority of image processing and machine learning algorithms. The first is scatter-gather, or the ability to read values from 32 addresses in L1 cache into vector registers in a single cycle. The CDNN2 compilation tool identifies serial code loading and implements vectorization to allow this feature, and scatter-gather improves data loading time when the data required is distributed through the memory structure. As the XM6 is configurable IP, the size/associativity of the L1 data store is adjustable at the silicon design level, and CEVA has stated that this feature will work with any size L1. The vector registers for processing at this level are 8-wide VLIW implementations, meaning 'feed the beast' is even more important than usual.

The second feature is called 'sliding-window' data processing, and this specific technique for vision processing has been patented by CEVA. There are many ways to process an image for either processing or intelligence, and typically an algorithm will use a block or tile of pixels at once to perform what it needs to. For the intelligence part, a number of these blocks will overlap, resulting in areas of the image being reused at different parts of the computation. CEVA's method is to retain that data, resulting in fewer bits being needed in the next step of analysis. If this sounds straightforward (I was doing something similar with 3D differential equation analysis back in 2009), it is, and I was surprised that it had not been implemented in vision/image processing before. Reusing old data (assuming you have somewhere to store it) saves time and saves energy.

CEVA is claiming up to a 3x performance gain in heavy vector workloads for XM6 over XM4, with an average of 2x improvement for like-for-like ported kernels. The XM6 is also more configurable than the XM4 from a code perspective, offering '50% more control'.

With the specific CDNN hardware accelerator (HWA), CEVA cites that convolution layers in ecosystems such as GoogleNet consume the majority of cycles. The CDNN HWA takes this code and implements fixed hardware for it with 512 MACs using 16-bit support for up to an 8x performance gain (and 95% utilization). CEVA mentioned that a 12-bit implementation would save die area and cost for a minimal reduction in accuracy, however there are a number of developers requesting full 16-bit support for future projects, hence the choice.
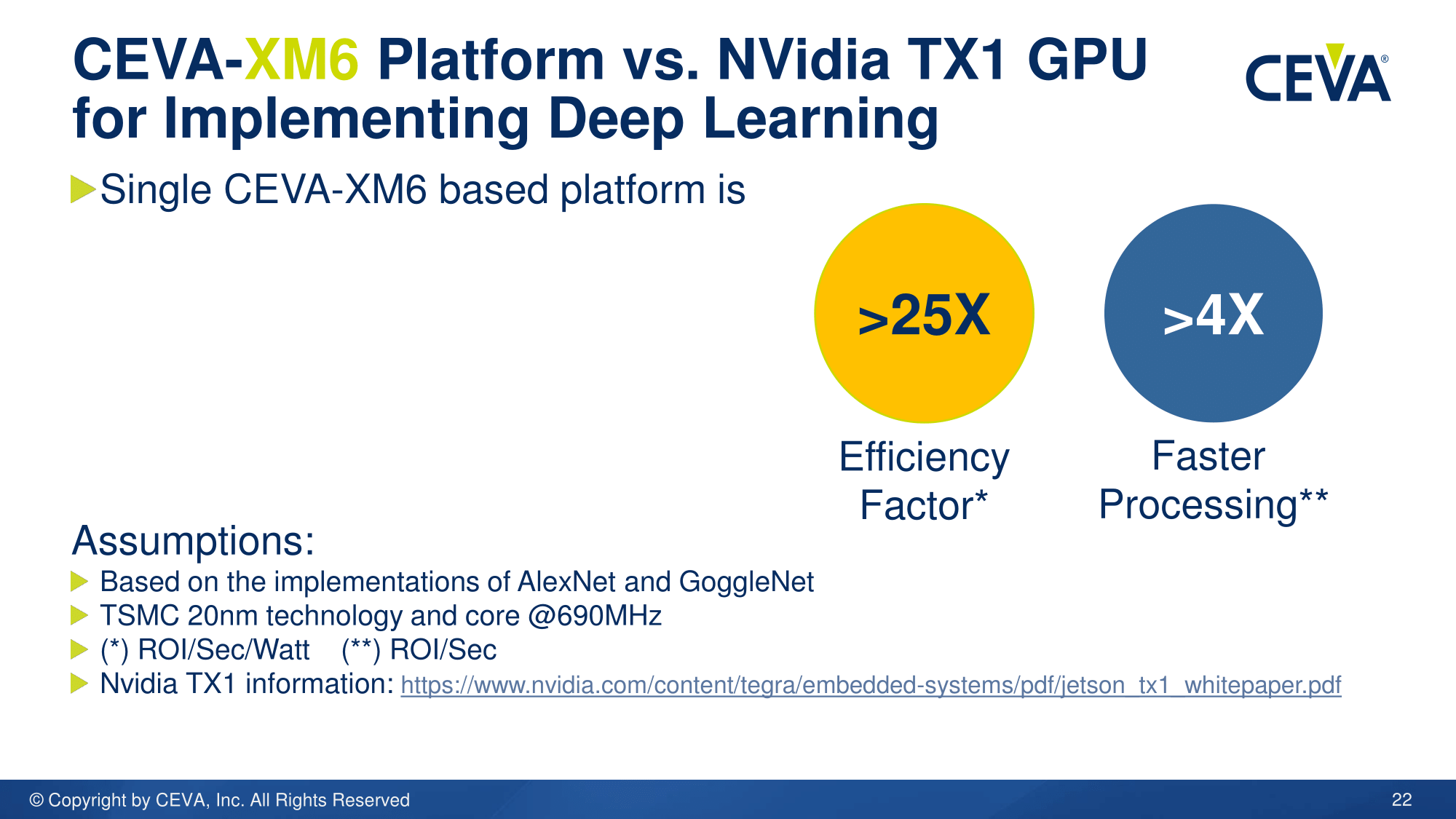
Two of the big competitors for CEVA in this space, for automotive image/visual processing, is MobilEye and NVIDIA, with the latter promoting the TX1 for both training and inference for neural networks. Based on TX1 on a TSMC 20nm Planar process at 690 MHz, CEVA states that their internal simulations give a single XM6 based platform as 25x the efficiency and 4x the speed based on AlexNet and GoogleNet (with the XM6 also at 20nm, even though it will most likely be implemented at 16nm FinFET or 28nm). This would mean, extrapolating the single batch TX1 data published, that XM6 using AlexNet at FP16 can perform 268 images a second compared to 67, at around 800 mW compared to 5.1W. At 16FF, this power number is likely to be significantly lower (CEVA told us that their internal metrics were initially done at 28nm/16FF, but were redone on 20nm for an apples-to-apples with the TX1). It should be noted that TX1 numbers were provided for multi-batch which offered better efficiency over single batch, however other comparison numbers were not provided. CEVA also implements power gating with a DVFS scheme that allows low power modes when various parts of the DSP or accelerators are idle.
Obviously the advantage that NVIDIA has with their solution is availability and CUDA/OpenCL software development, both of which CEVA is attempting to address with one-button software platforms like CDNN2 and improved hardware such as XM6. It will be interesting to see which semiconductor partners and future implementations will combine this image processing with machine learning in the future. CEVA states that smartphones, automotive, security and commercial (drones, automation) applications are prime targets.






Source: CEVA








3 Comments
View All Comments
p1esk - Tuesday, September 27, 2016 - link
Interesting, but we should see how it compares to Pascal based Jetson chip. TX1 is over a year old at this point, while this processor does not even exist yet.However, 0.8W is impressive, and if it can process 60fps video input, or at least 30fps, it could be a hit for smartphones, cameras, drones, etc.
OliverFFF - Wednesday, December 30, 2020 - link
It's an interesting image and can be useful in my machine learning studying. It's a little bit hard for me, so I often try to find some additional resources, e.g. https://assignmentbro.com/us/ , to go deeper into the theme. Eventually, such assignment services are beneficial for students in any case.car designer - Tuesday, January 25, 2022 - link
Thank you for this detailed publication. We partially use this technology when creating car images on https://hum2d.com/Using this data has allowed us to significantly reduce the time spent on car clipart design.