Hot Chips 2018: Xilinx DNN Processors Live Blog
by Ian Cutress on August 21, 2018 6:55 PM EST- Posted in
- SoCs
- Hot Chips
- Trade Shows
- Semiconductors
- Xilinx
- Live Blog
- DNN

06:56PM EDT - Xilinx has several talks this year at Hot Chips, and aside from the ACAP earlier in the day, the talk about their Deep Neural Network processor also looks interesting. The talk is set to start at 4pm PT / 11pm UTC.

07:01PM EDT - Xilinx Inference Engine - DNN Processor for Xilinx FPGA and software tools
07:02PM EDT - No FPGA expertise required
07:02PM EDT - Low latency, high throughput
07:02PM EDT - All work shown was performed on Ultrascale+ VU9P

07:03PM EDT - FPGA maps well to Deep Learning
07:04PM EDT - Flexible on-chip memory, high bandwidth, multiple acess ports
07:04PM EDT - Near memory compute, for power

07:04PM EDT - Can do variable data types
07:05PM EDT - INT2 to FP32 and beyond
07:05PM EDT - Binary / Ternary
07:05PM EDT - Sparse friendly compute
07:05PM EDT - Uses a full scale or memory

07:07PM EDT - Configurable overlay processor

07:08PM EDT - DNN specific instruction set
07:08PM EDT - Any network, any image size
07:08PM EDT - high frequency and high compute
07:08PM EDT - Compile and run new networks
07:09PM EDT - Systolic array is a 2D channel parallel datapath and distributed weight buffers

07:09PM EDT - All the processing elements are mapped on the DSP blocks with weight buffers
07:09PM EDT - The distributed RAMs are close to the weight blocks as a cache
07:09PM EDT - feed it to the DSP block
07:10PM EDT - Ping pong architecture
07:10PM EDT - Get the weights from DDR in ping and use on pong
07:10PM EDT - DSP block has been optimized for INT16 and INT8
07:10PM EDT - INT8 maps as 2 Multiply-Add on each block
07:10PM EDT - Fun Multiply Accumualte at 2x clock, memory access at clock speed
07:11PM EDT - Cascaded along the columns
07:11PM EDT - Columns mapped to output maps
07:11PM EDT - Microarchitecture optimized for underlying Ultrascale+ FPGA Fabric
07:11PM EDT - Tensor memory next to systolic array
07:12PM EDT - Channel parallel concurrent access
07:12PM EDT - Mapped to UltraRAMs
07:14PM EDT - Memory utilization is optimized as well
07:15PM EDT - compiler schedules data reuse
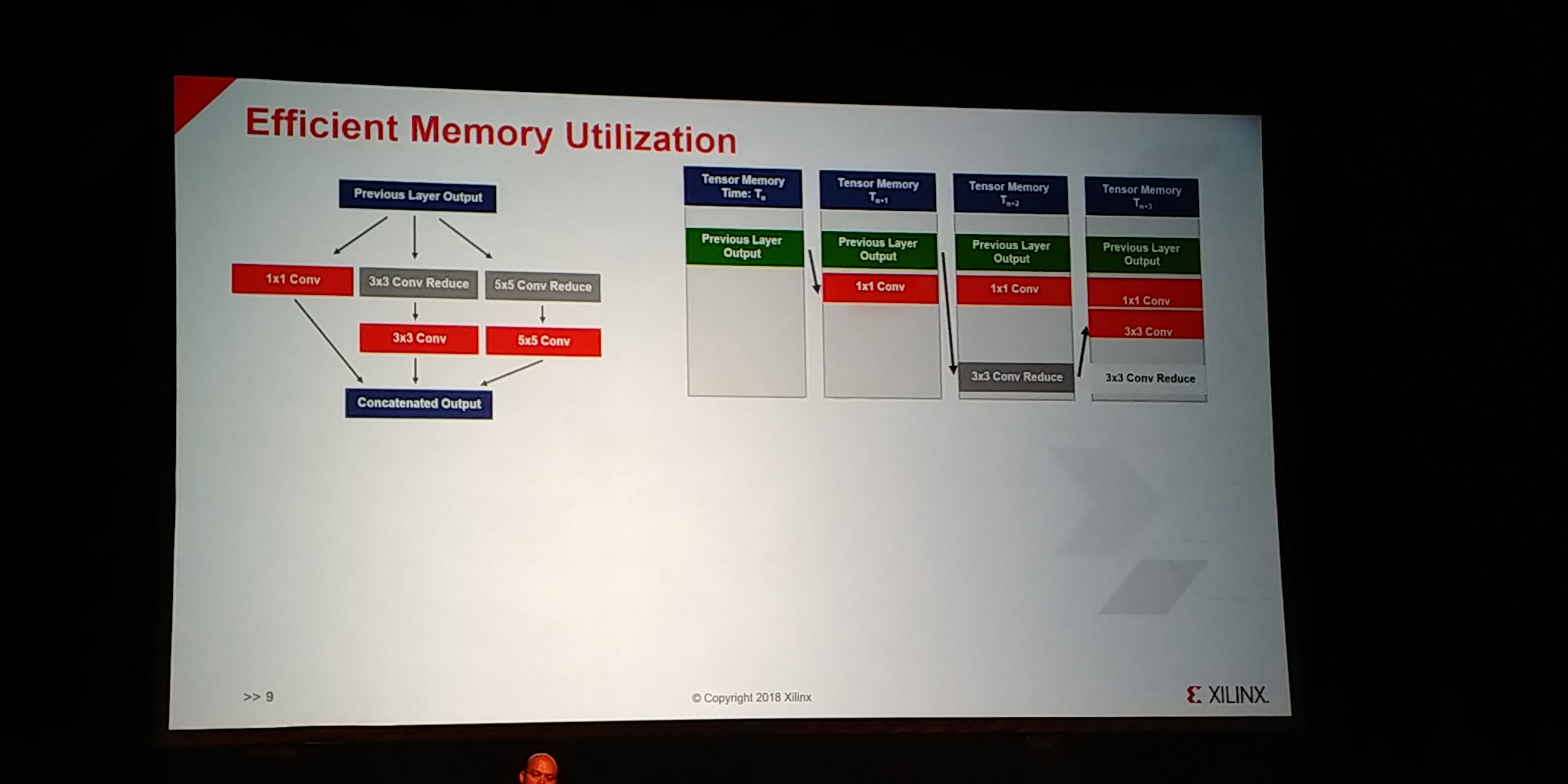
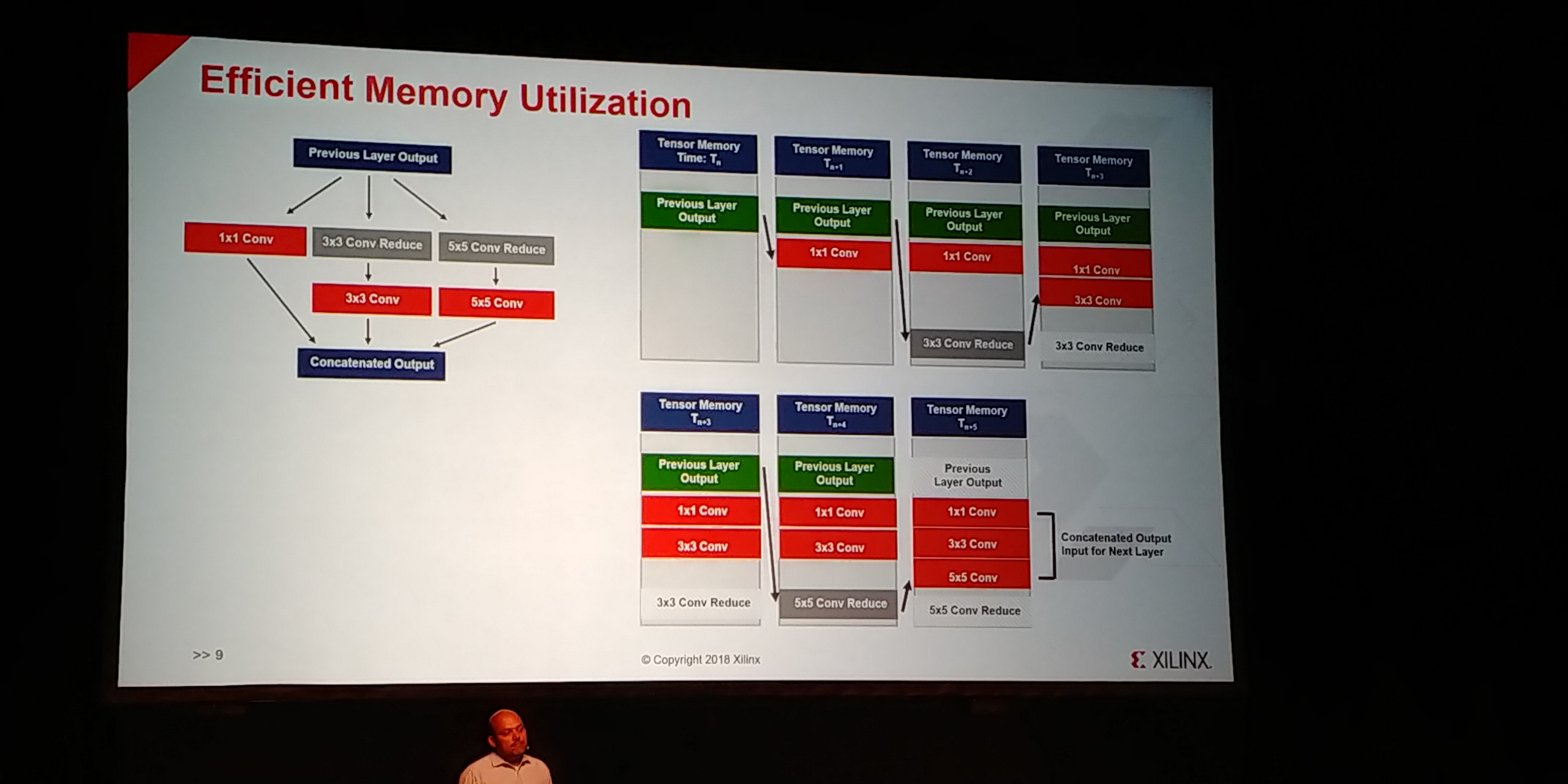
07:15PM EDT - Output through memory addresses get concatinated for input to next layer
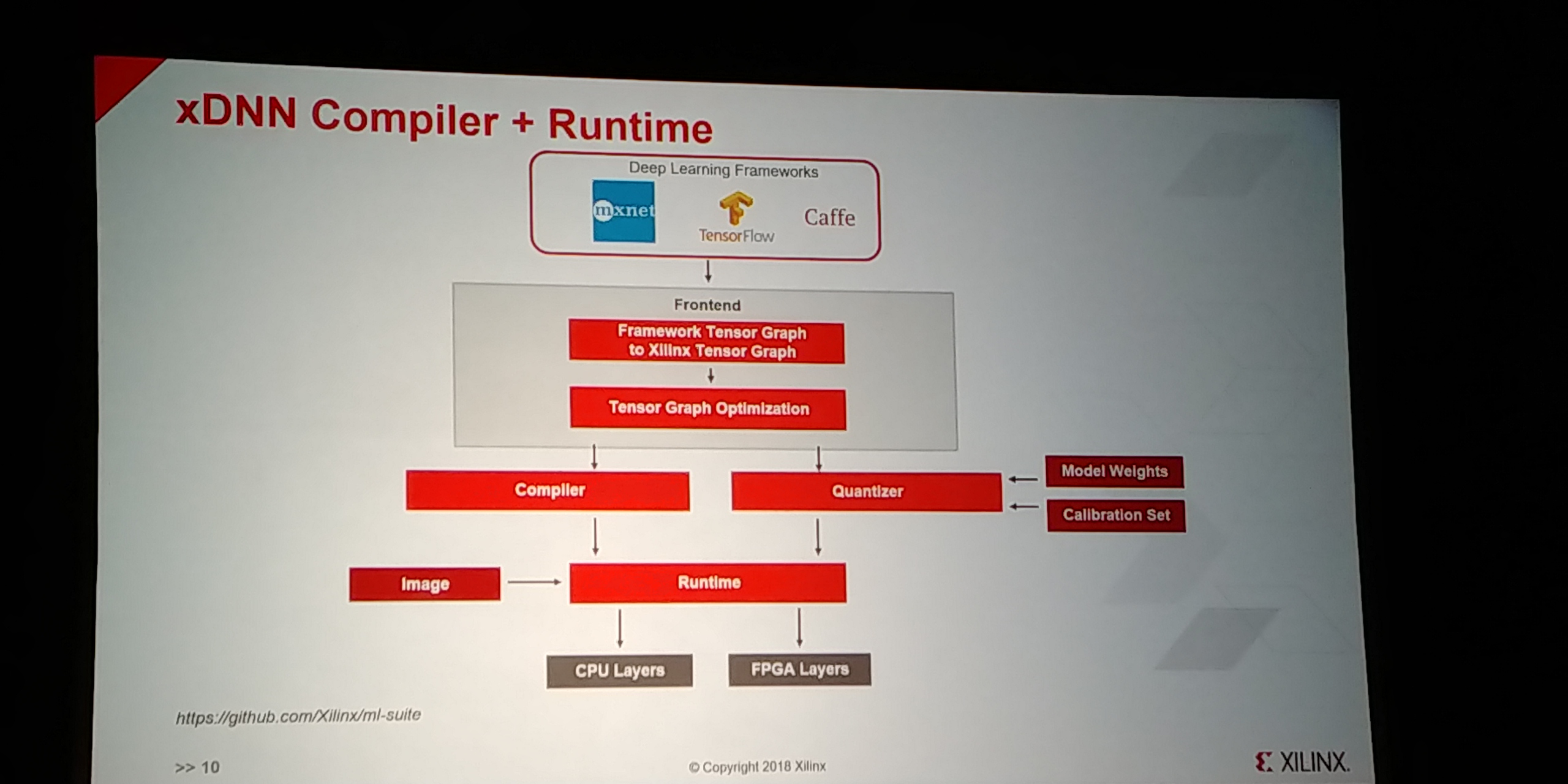
07:15PM EDT - Full middleware tools and API
07:16PM EDT - Caffe, Tensorflow and mxnet
07:16PM EDT - Give the trained model and the weights, convert into Xilinx Graph, does few optimizations, then goes to the compiler to run the network on the DNN on the FPGA
07:16PM EDT - Also have a quantizer, done offline
07:17PM EDT - Runtime manages all the communication between CPU and FPGA
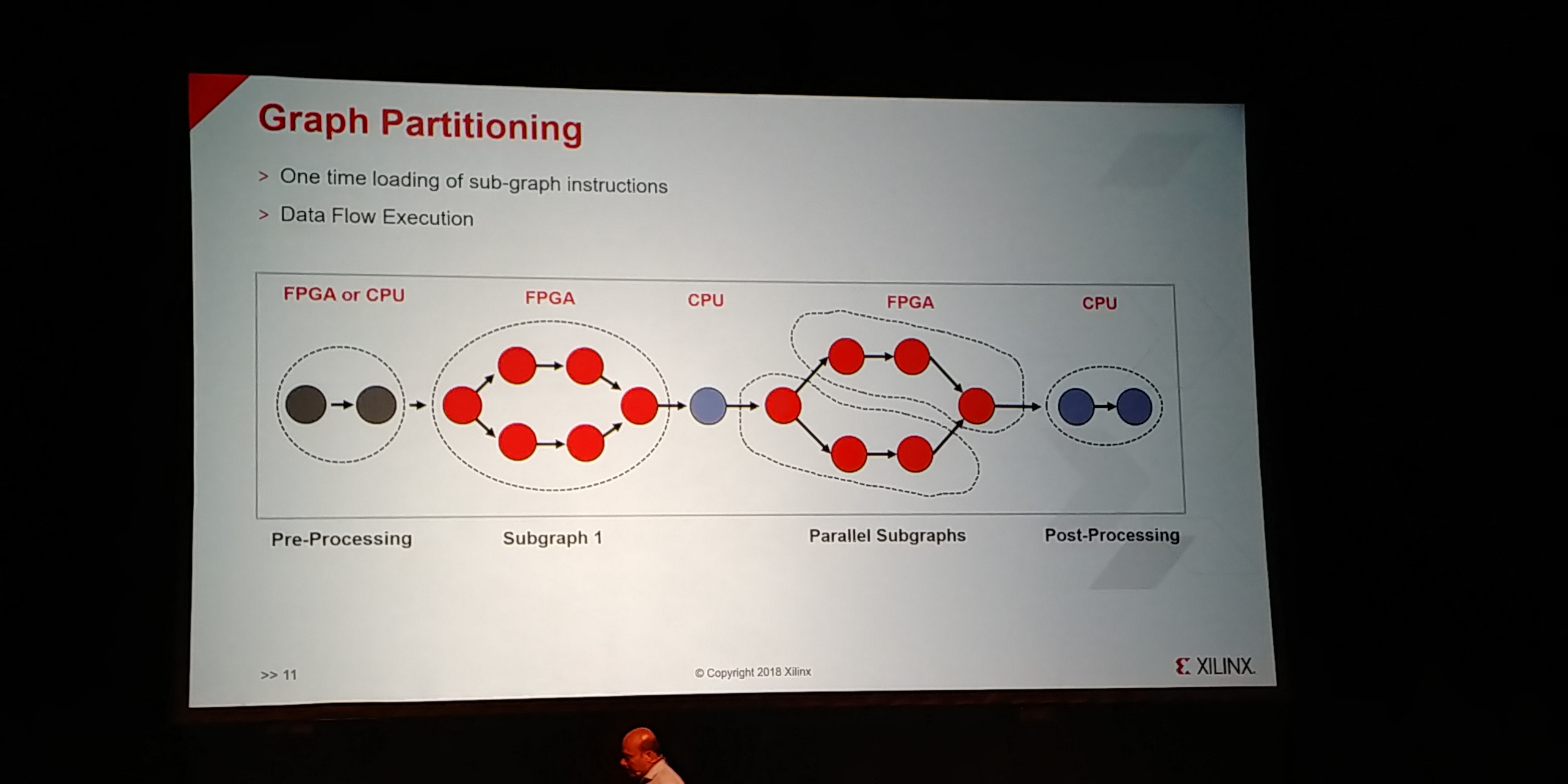
07:17PM EDT - Compiler does graph partitioning and optimizing
07:17PM EDT - one-time loading of sub-graph instructions
07:17PM EDT - Splits up data depending on chips available
07:18PM EDT - Fusing of operations into pipeline stages
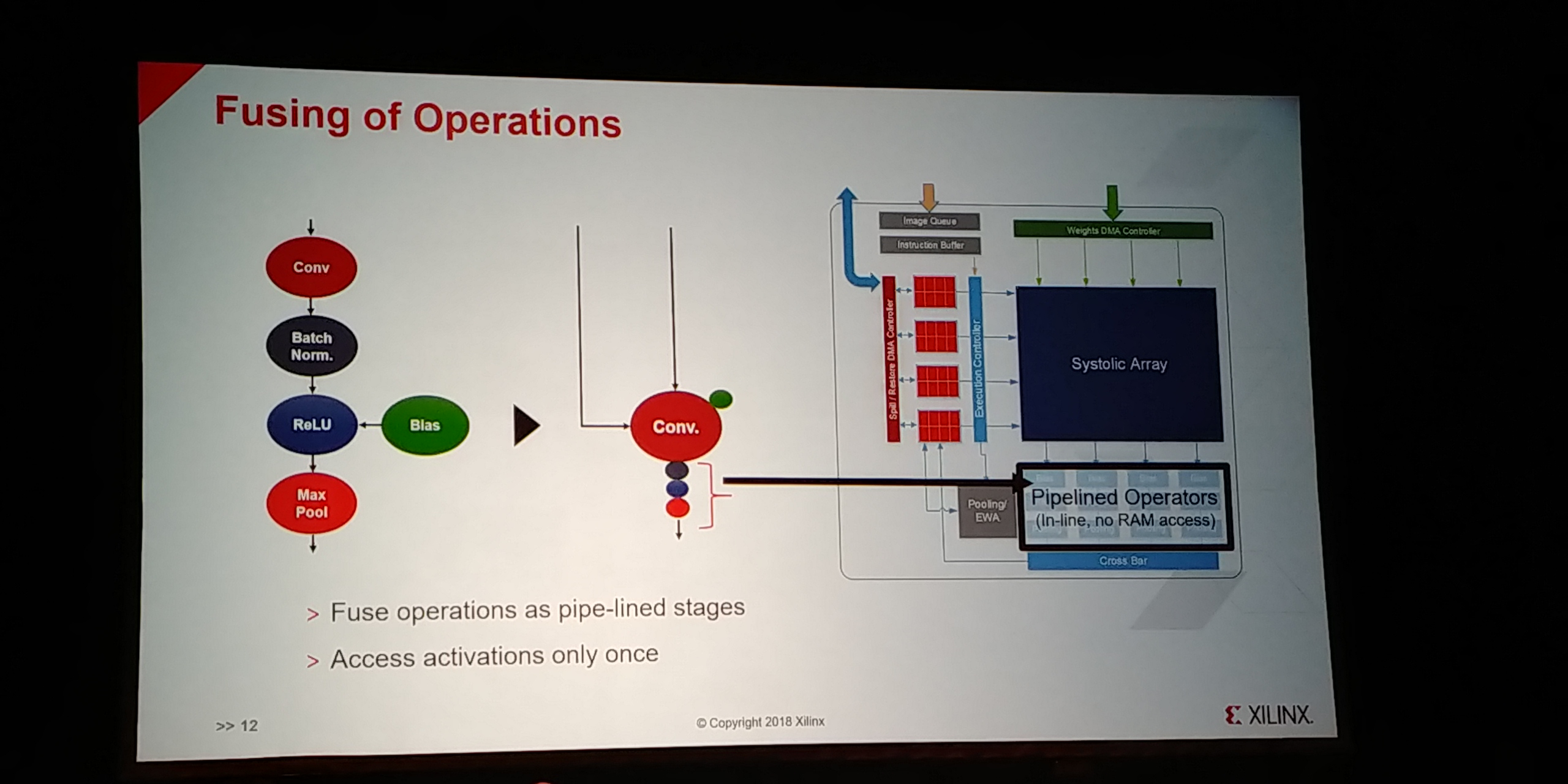
07:18PM EDT - access activations only once, into pipelined operators with no RAM access
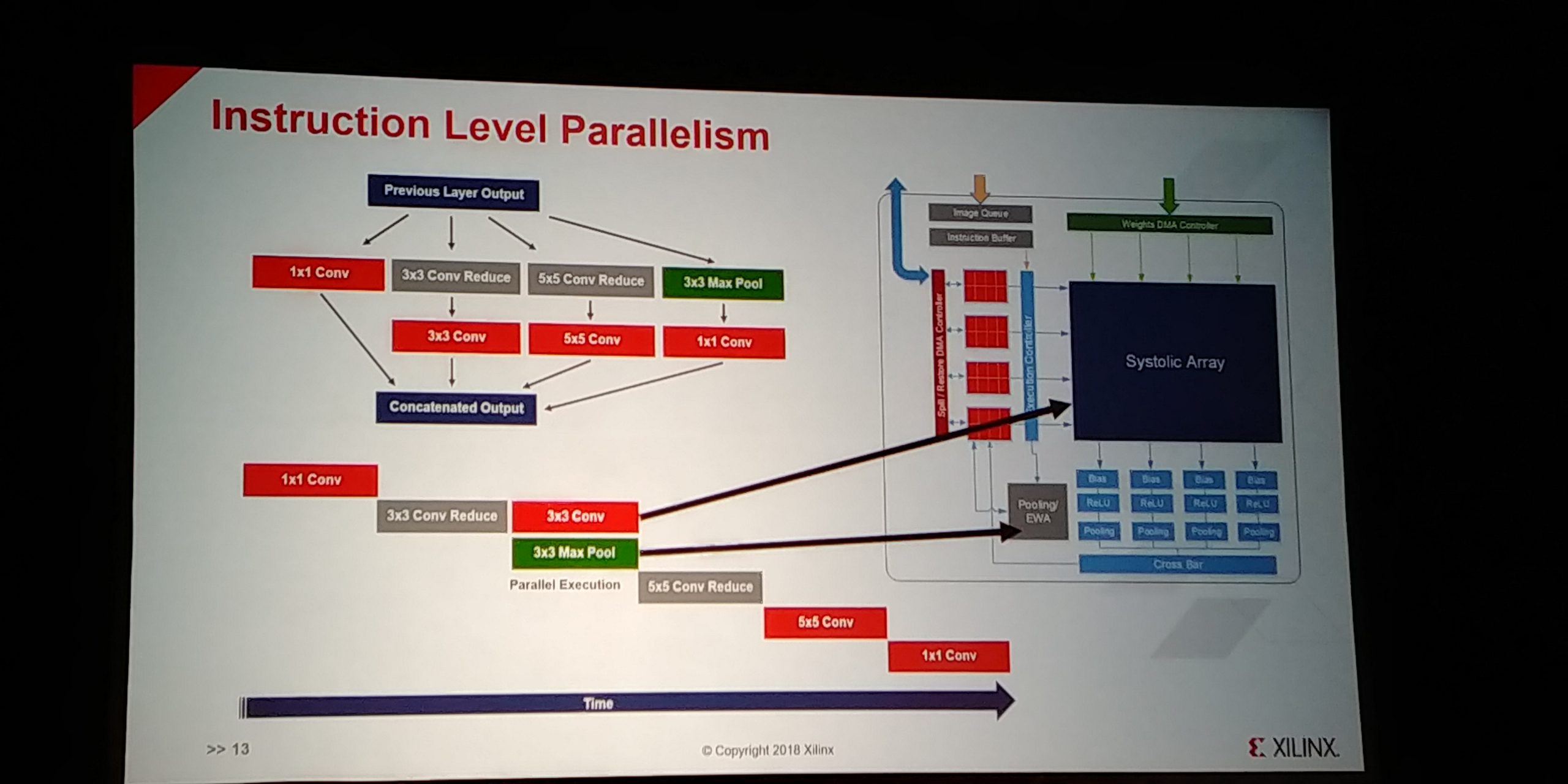
07:18PM EDT - Has an amount of Instruction Level Parallelism where possible
07:19PM EDT - Can schedule parallel instructions
07:19PM EDT - Automatic Intra-Layer Tiling when map size exceeds on chip memory
07:19PM EDT - any feature map size

07:20PM EDT - Hardware does the tiling automatically
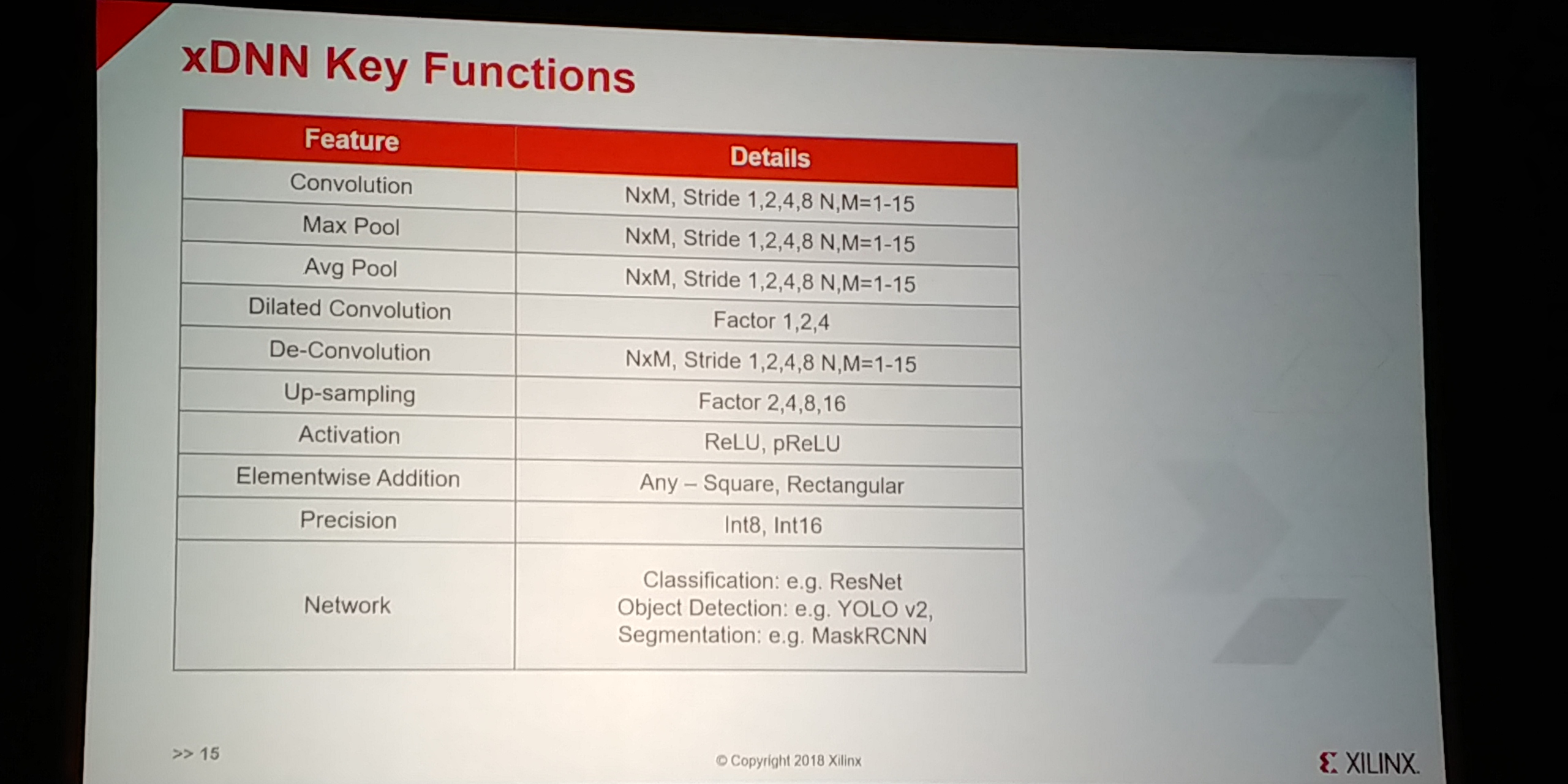
07:20PM EDT - Key functions: INT8 and INT16
07:21PM EDT - Supports square and rectangular sizes
07:21PM EDT - Various networks

07:22PM EDT - 96x16 PEs, 1 in each SLR
07:22PM EDT - 90% of the maximum device frequency
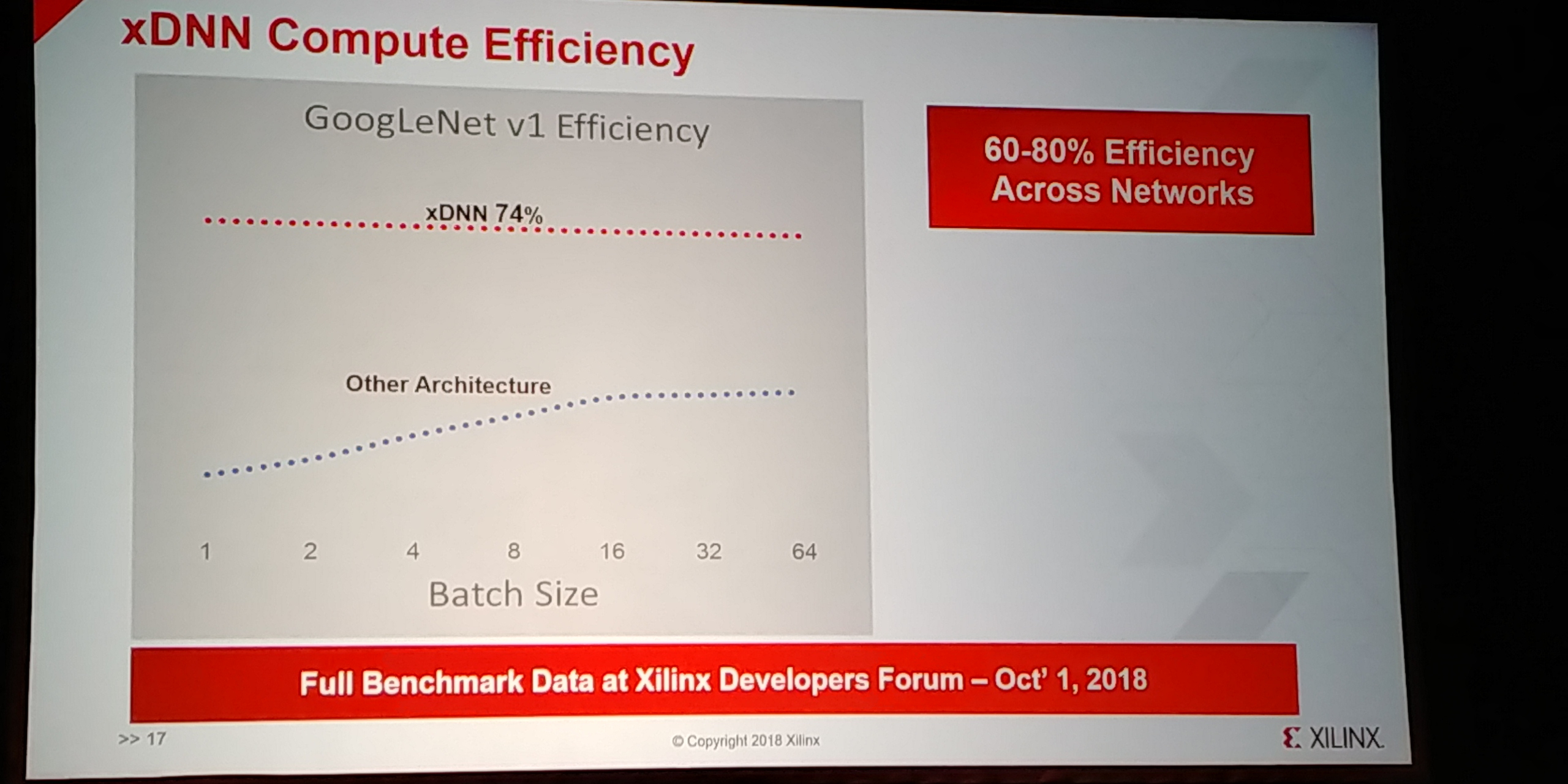
07:23PM EDT - Launching the IP as a product at the Xilinx Developer Forum, Oct 1st
07:23PM EDT - Also custom DL pipelining
07:23PM EDT - All Pipelines can be running the same networks or different networks
07:23PM EDT - Or leading data from one to another
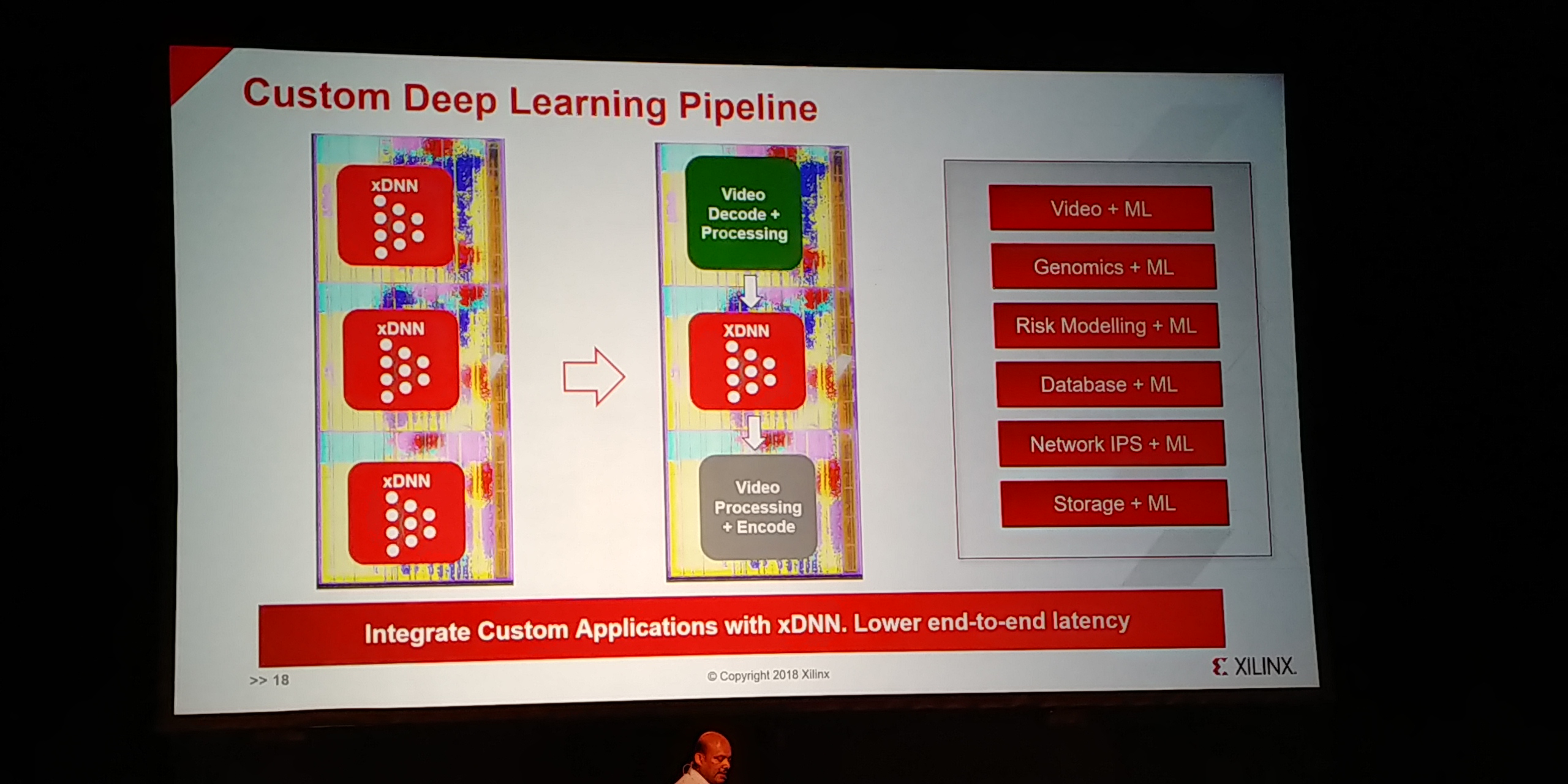
07:24PM EDT - Deploy in cloud or on PCIe cards
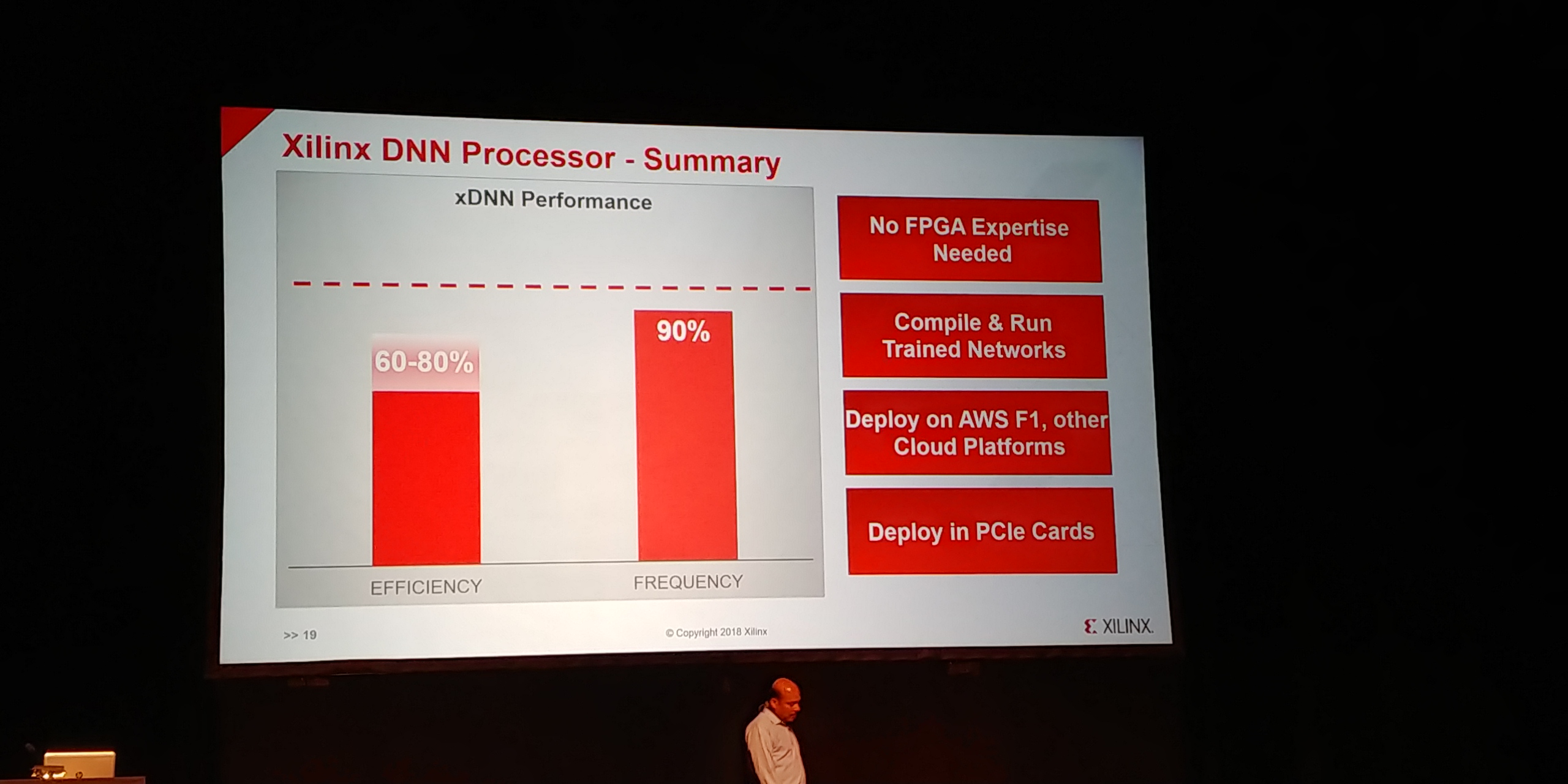
07:24PM EDT - No FPGA experience needed
07:25PM EDT - Xilinx Dev Forum - Silicon Valley, Beijing, Frankfurt
07:25PM EDT - Q&A Time
07:26PM EDT - Q: You showed 90% of Fmax with 50% of LUTs. Can you add another application in the spare area? A: Yes.But you are using 92% of the UltraRAMs, so it will have to avoid those. Might want to only map one or two engines, not all three
07:29PM EDT - Q: A lot of research in new topologies. How do you support these new features? A: If you have new features that don't map, you can map into the FPGA. Or run on CPU.
07:30PM EDT - Q: Today Xilinx announced ACAP. What is perforamnce? A: This xDNN is about 16nm. We will make it mapped on the ACAP as well in time. Performance will increase.
07:30PM EDT - That's a wrap. 30 minute break, and then the server talks.








3 Comments
View All Comments
p1esk - Tuesday, August 21, 2018 - link
I'm curious about performance per watt for ternary networks. Should be off the charts. Unfortunately that's pretty much the only use case where they can compete with GPUs.anoldnewb - Thursday, August 23, 2018 - link
What is cost vs GPUkfishy - Monday, August 27, 2018 - link
Virtex Ultrascale+ is going to be order of magnitude more expensive than a GPU. Cheapest one from Digikey is 15K.