Hot Chips 2020 Live Blog: Intel 10nm Agilex FPGAs (8:30am PT)
by Dr. Ian Cutress on August 18, 2020 10:50 AM EST
11:27AM EDT - First Session of Day 2 is on FPGAs, with Intel's 10nm Agilex up first

11:27AM EDT - I saw one last year at a Stratix 10 briefing

11:30AM EDT - And here we go, presentation about to begin
11:31AM EDT - Ralph Wittig from Xilinx is the session chair


11:32AM EDT - Agilex is Intel's first in-house FPGA
11:32AM EDT - customized 10nm process
11:32AM EDT - 40% higher perf, 40% lower power, compared to Stratix
11:32AM EDT - Supports up to 116 Gbps
11:33AM EDT - Variants will support CXL, DDR4/DDR5, HBM2e and Optane

11:33AM EDT - Agilex is the Spatial component in its strategy - also supports OneAPI
11:33AM EDT - Second gen EMIB
11:33AM EDT - Disaggregated transceivers and HBM tiles
11:34AM EDT - Meets specific customer needs

11:34AM EDT - Programming logic is kept monolithic
11:34AM EDT - Floorplan has improved
11:34AM EDT - Smooth fabric grid without I/O disruptions
11:34AM EDT - No notches in the fabric
11:35AM EDT - Arm processor complex has been moved to the corners to eliminate those notches
11:35AM EDT - Rectangular fabric simplifies customer routing
11:35AM EDT - Identical resourcing across the fabric
11:35AM EDT - Quad Arm A53 sub-system, ECC L1/L2 with snoop control
11:36AM EDT - Secure Device Manager, triple redundant hard processor, crypto, SEU events, device boot order
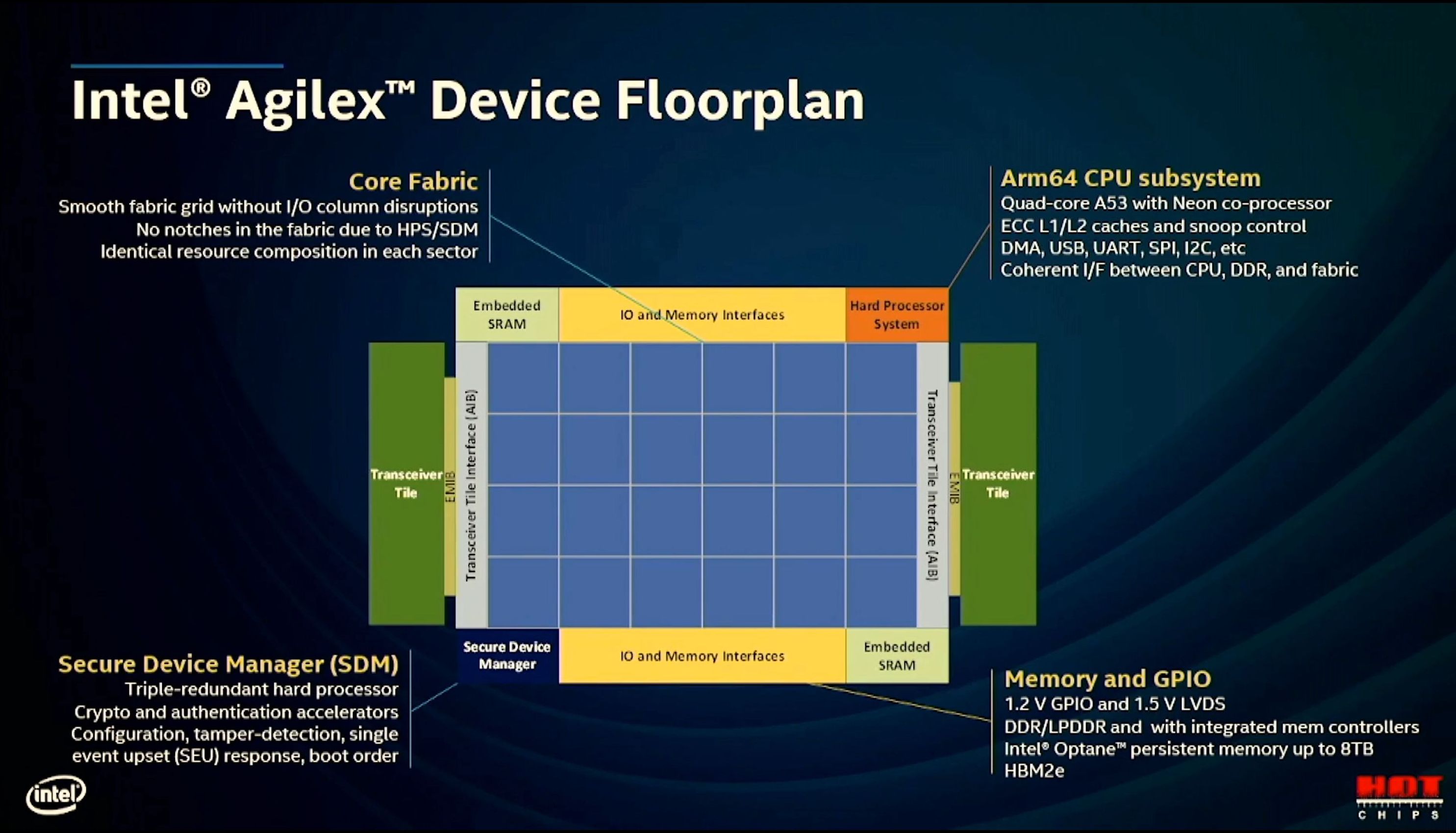
11:36AM EDT - Memory and GPIO
11:36AM EDT - Up to 8TB support with HBM2e
11:36AM EDT - *Up to 8TB with Optane, HBM2e is separate
11:36AM EDT - EMIB bridges are 'AIB'
11:37AM EDT - Five types of tiles for Agilex
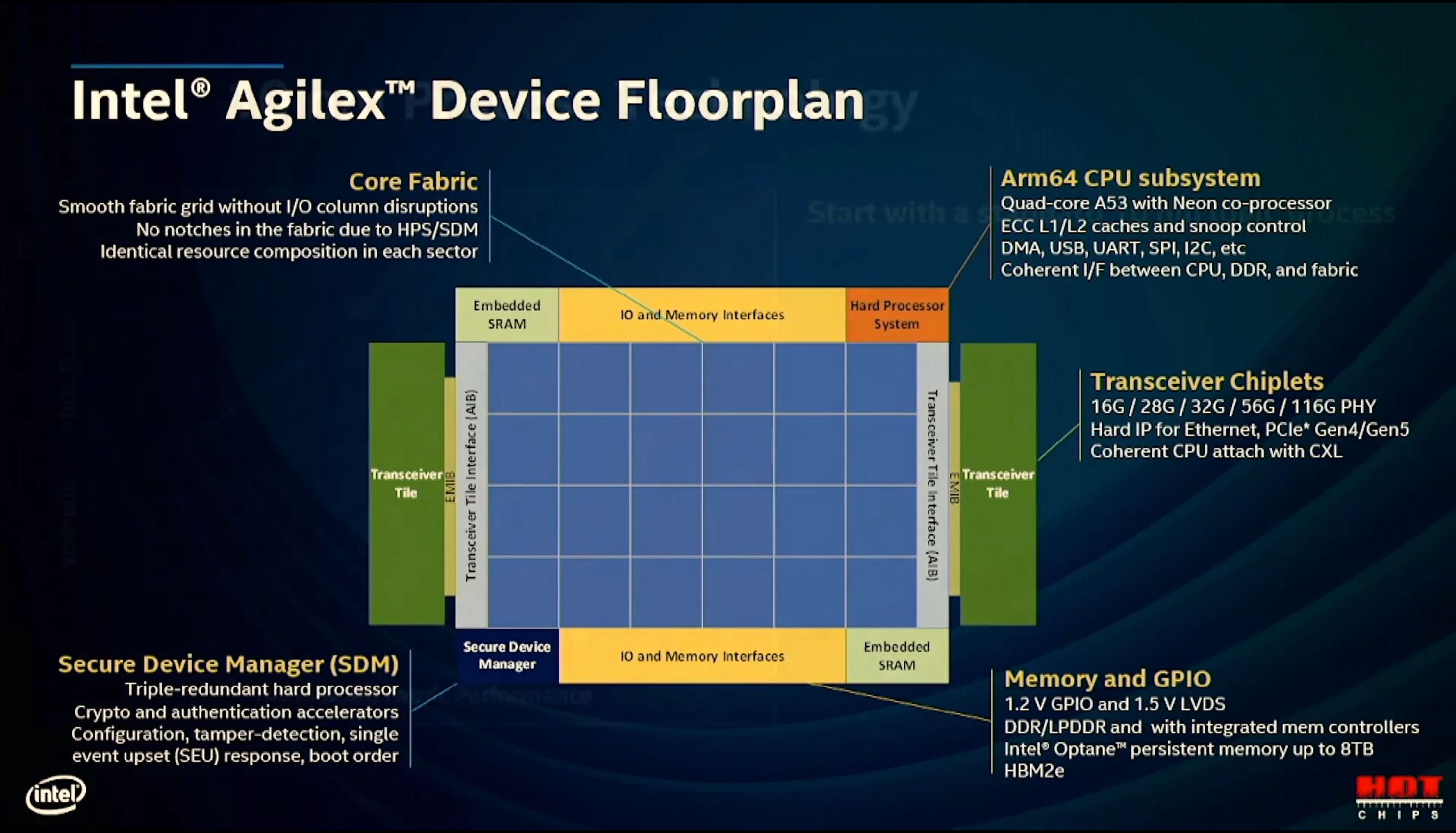
11:37AM EDT - Trancievers, PCIe 4, PCIe 5, Ethernet, CXL
11:37AM EDT - Uses Intel's standard 10nm process with customizations
11:37AM EDT - Metal stack improvments
11:38AM EDT - wider poly pitch, Vt tuning, custom layouts and dummy fill enhancements

11:38AM EDT - Each fabric sector has columns of logic and memory
11:38AM EDT - Logic speed +50%
11:38AM EDT - BF16, FP19, FP16, INT8 increased throughput
11:39AM EDT - Programmable clock delays
11:39AM EDT - Hyperflex ties all the blocks together
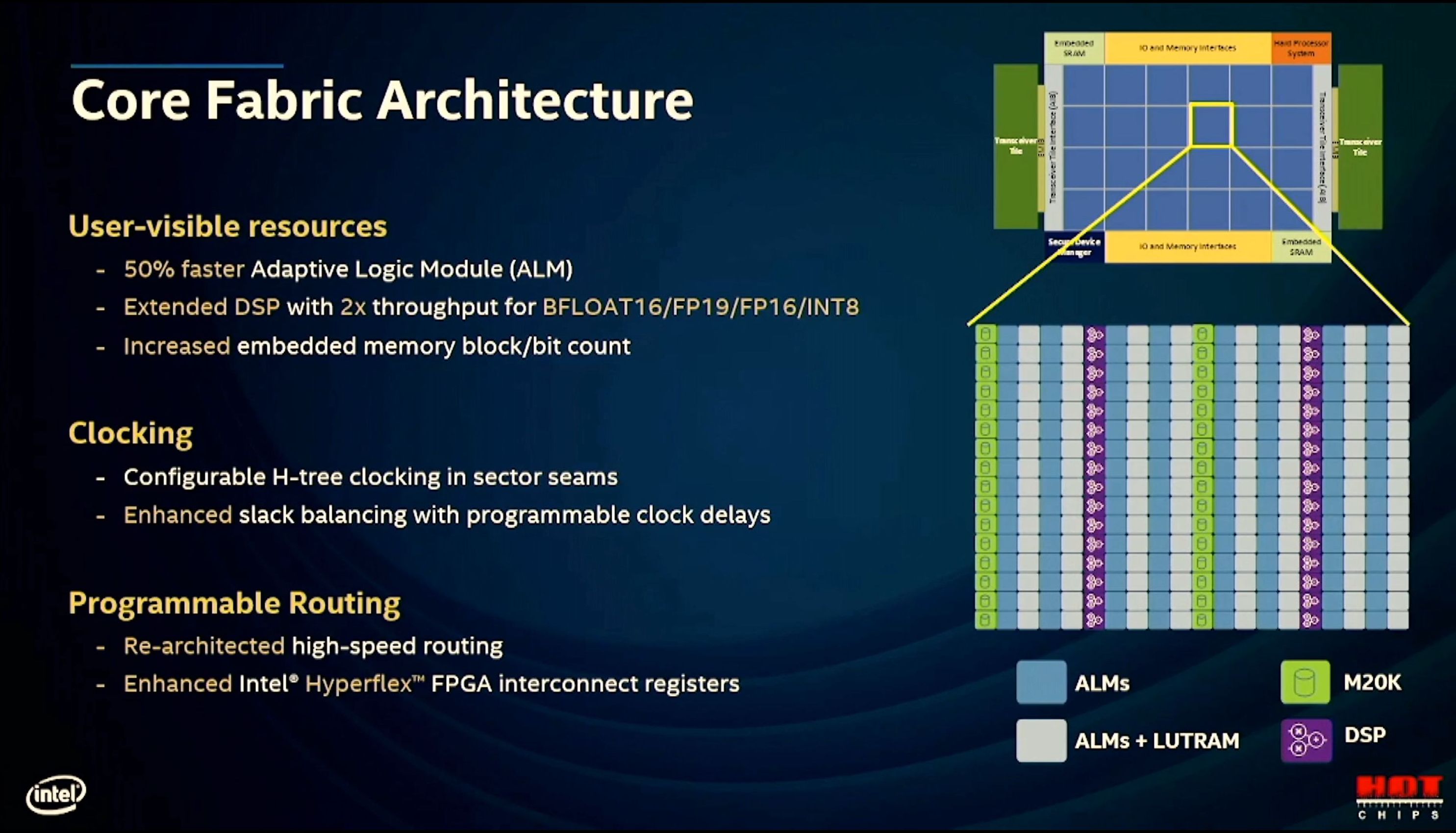
11:40AM EDT - Old - Mux -> Buffer -> Signal across columns. Fan out to other muxes. High FI/FO didn't scale to 10nm
11:40AM EDT - Now narrow low fan out muxes and redesigned routing pattern
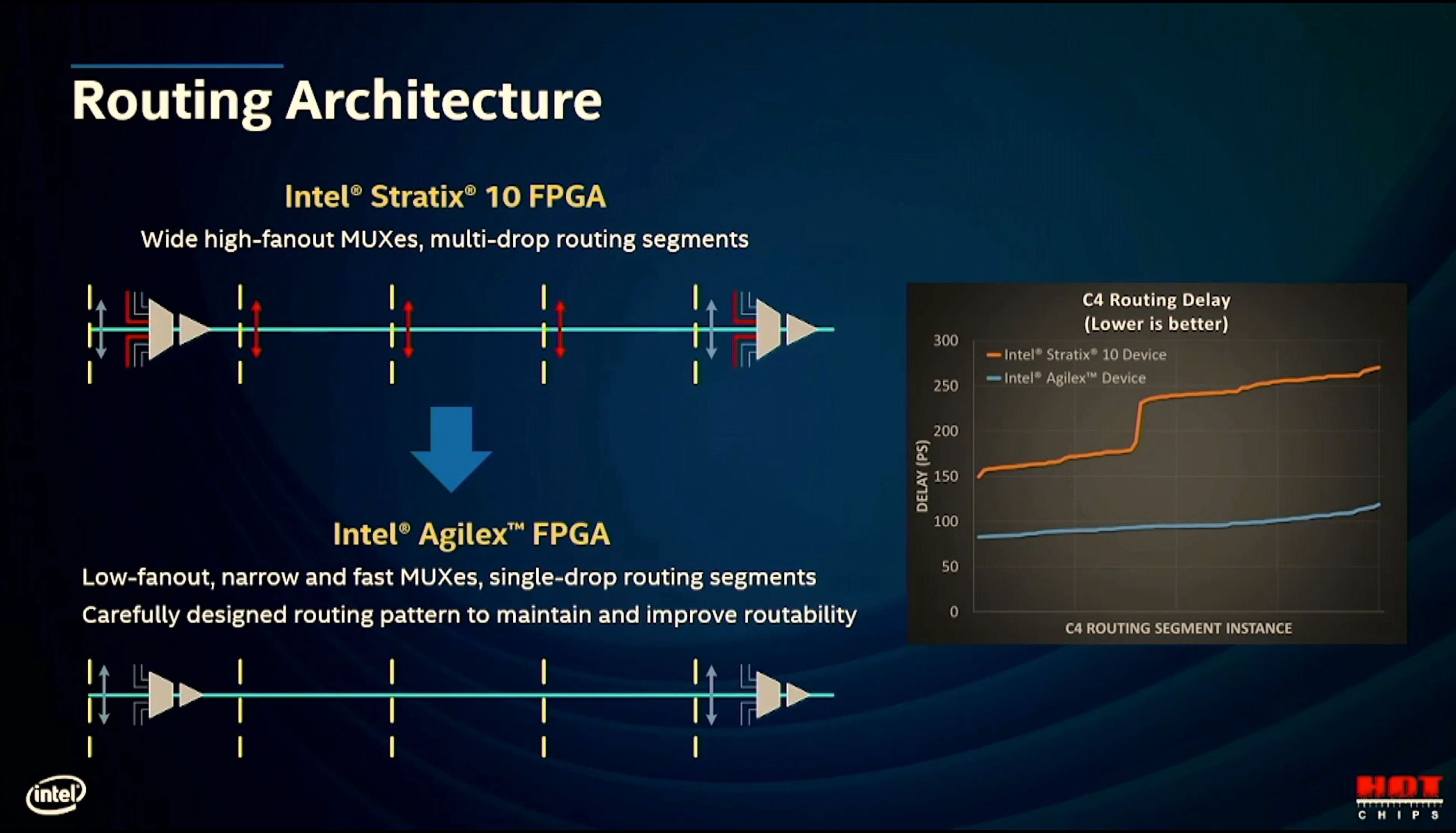
11:40AM EDT - C4 routing delay has a big improvement
11:41AM EDT - Agilex has repartitioned crossbar, allows suppor of narrower faster muxes
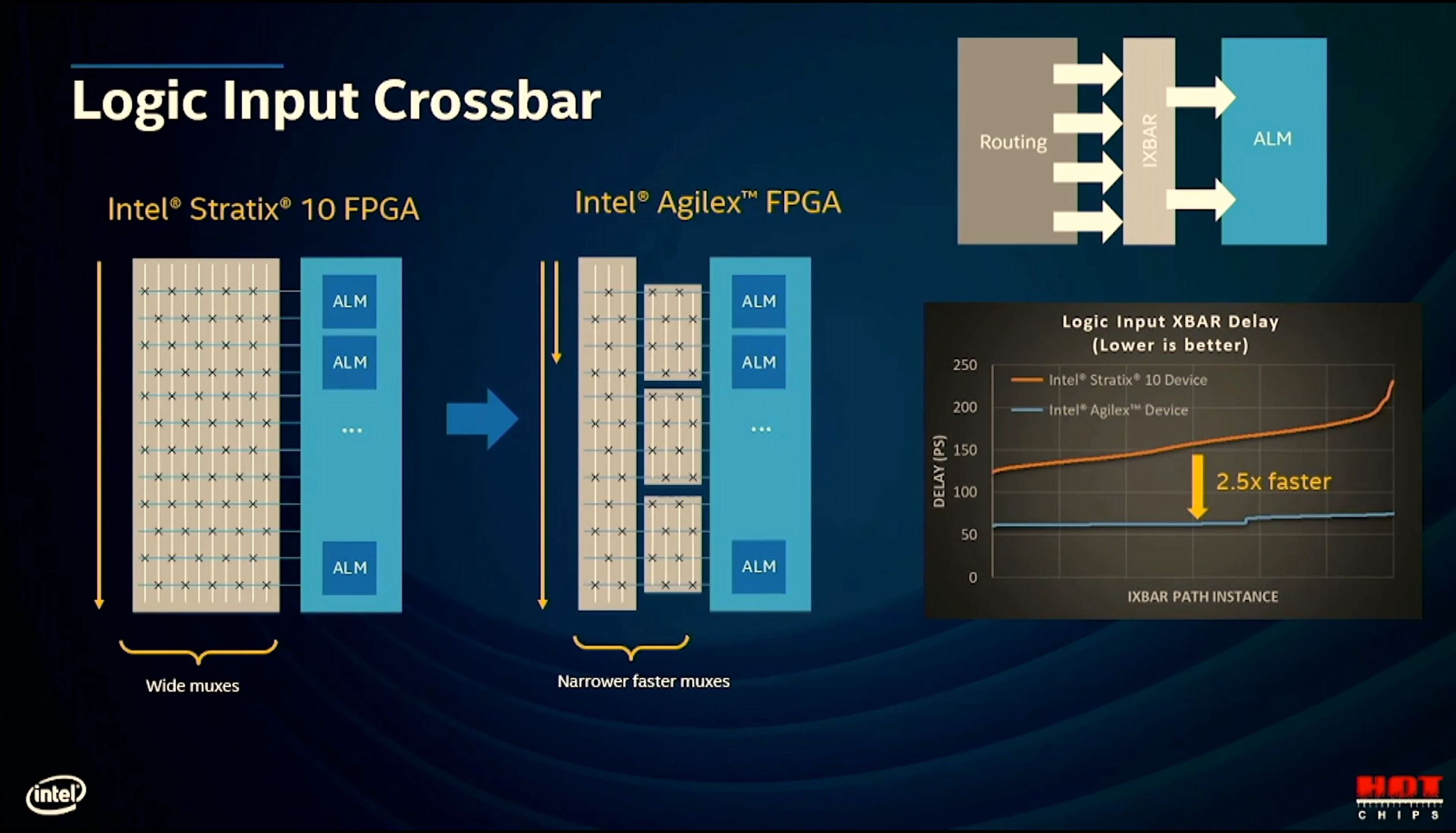
11:41AM EDT - 2.5x faster vs stratix10 crossbar delay
11:42AM EDT - 40%+ geomean Fmax improvement
11:42AM EDT - Using same code as Stratix without any change
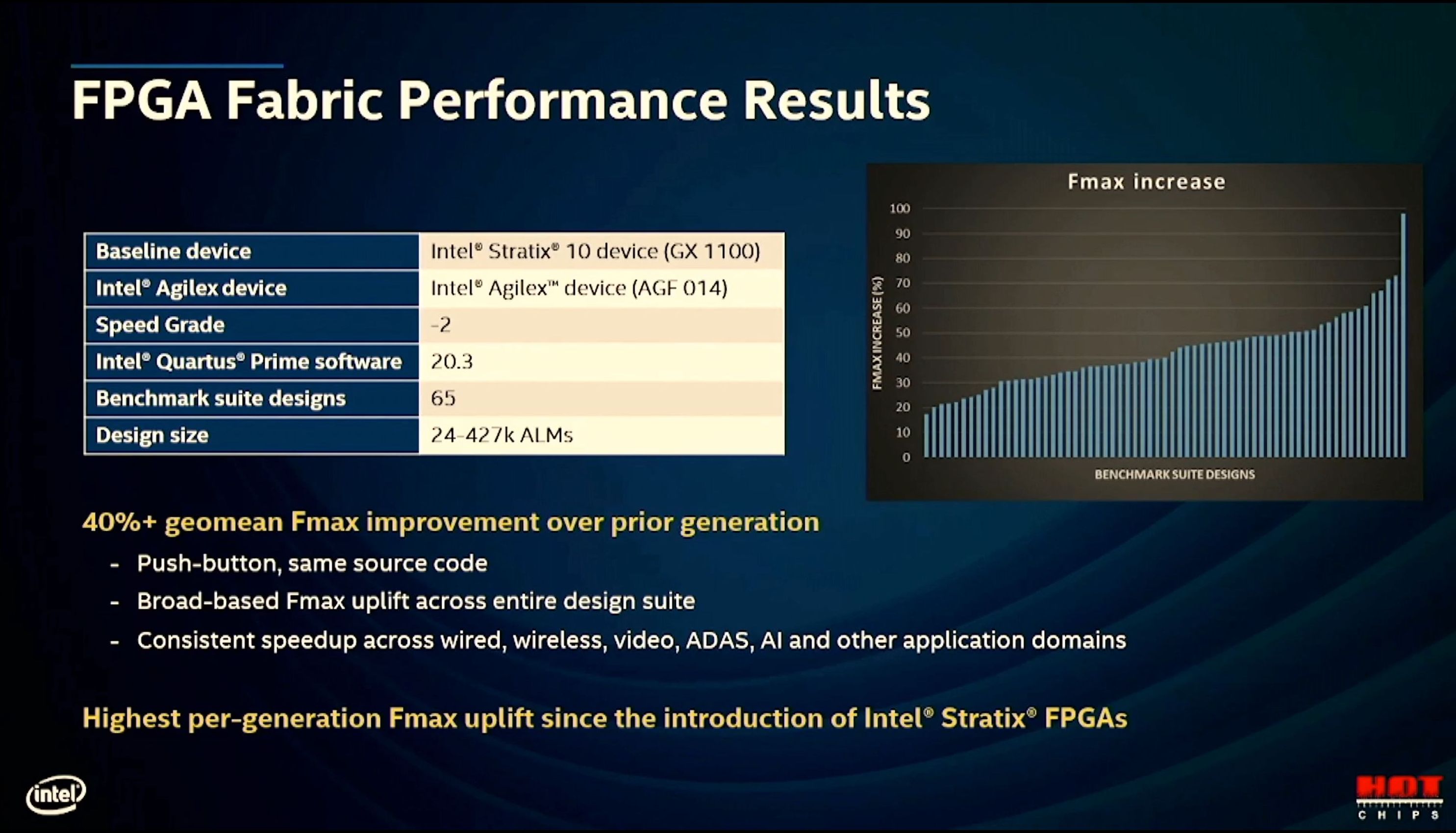
11:43AM EDT - Comparing GX1100 with Agilex AGF014

11:43AM EDT - Five tile types
11:43AM EDT - New R-Tile for Agilex - PCIe5 and CXL
11:43AM EDT - 16 lanes of 32 Gbps NRZ per tile

11:44AM EDT - Full support for CXL 1/2/3 configs
11:44AM EDT - F-Tile is high speed networking
11:44AM EDT - Two groups of transceiver PHYs
11:44AM EDT - Up to 116G
11:45AM EDT - Bifurcatable up to 400 GbE
11:45AM EDT - PCIe 4 x16
11:46AM EDT - 1e-7 BER in 116G, two order of magnitudes better than the standard requires

11:46AM EDT - Different Agilex families
11:47AM EDT - F-Series, I-Series, M-Series. The images at the beginning of the blog was F-Series


11:48AM EDT - Now to software and OneAPI

11:48AM EDT - Programmable registers at every stage
11:48AM EDT - ASIC-style clocking architecture
11:48AM EDT - Quartus software co-designed with the hardware
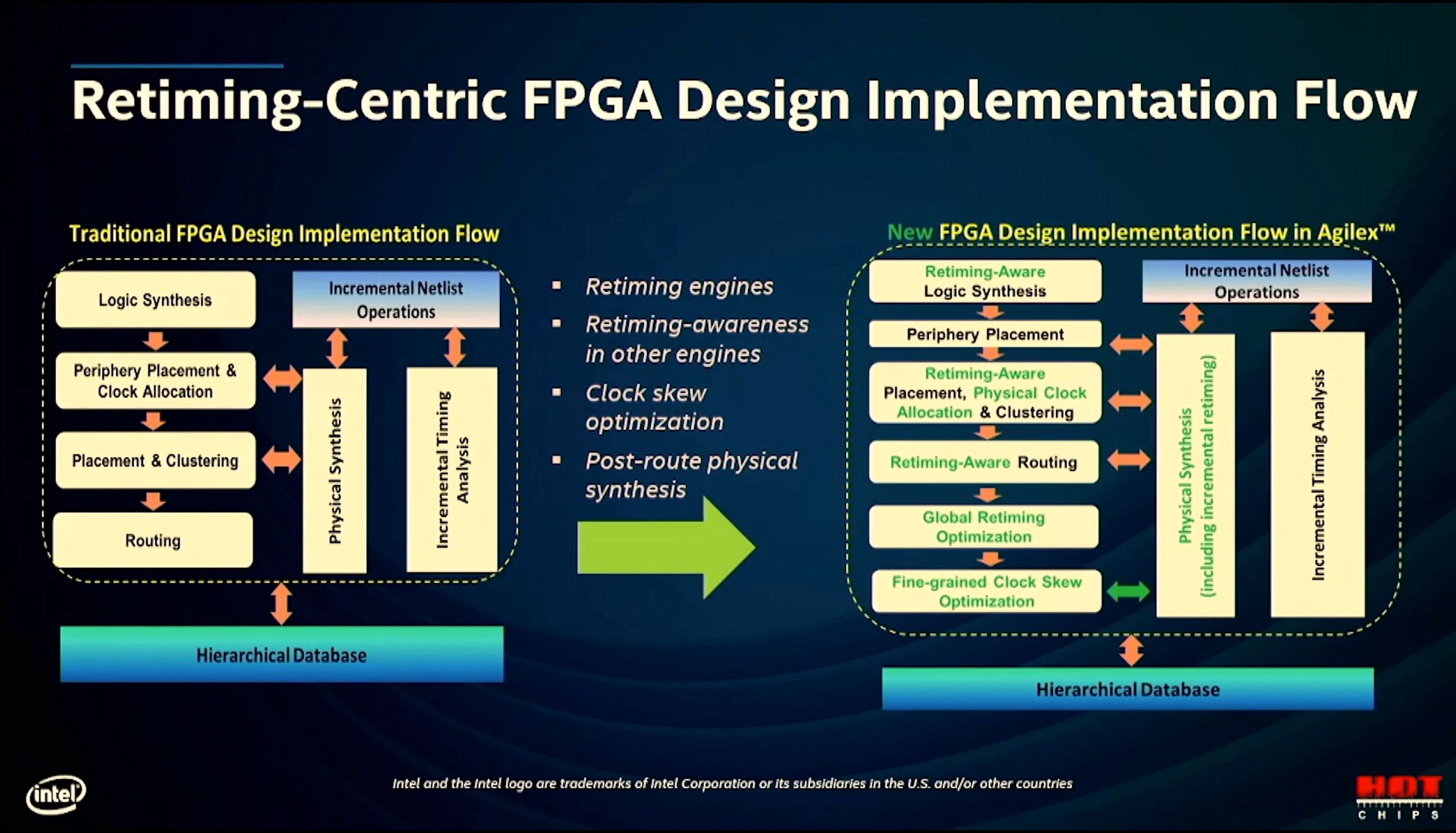
11:49AM EDT - Quartus has been revamped to be timing-centric
11:49AM EDT - Accurate delays without rerouting connections
11:49AM EDT - Additional Fmax unlocks
11:50AM EDT - Retiming aware that can fix critical paths
11:50AM EDT - Design specific clock routing
11:51AM EDT - Sequential circuit optimization technique for Fmax
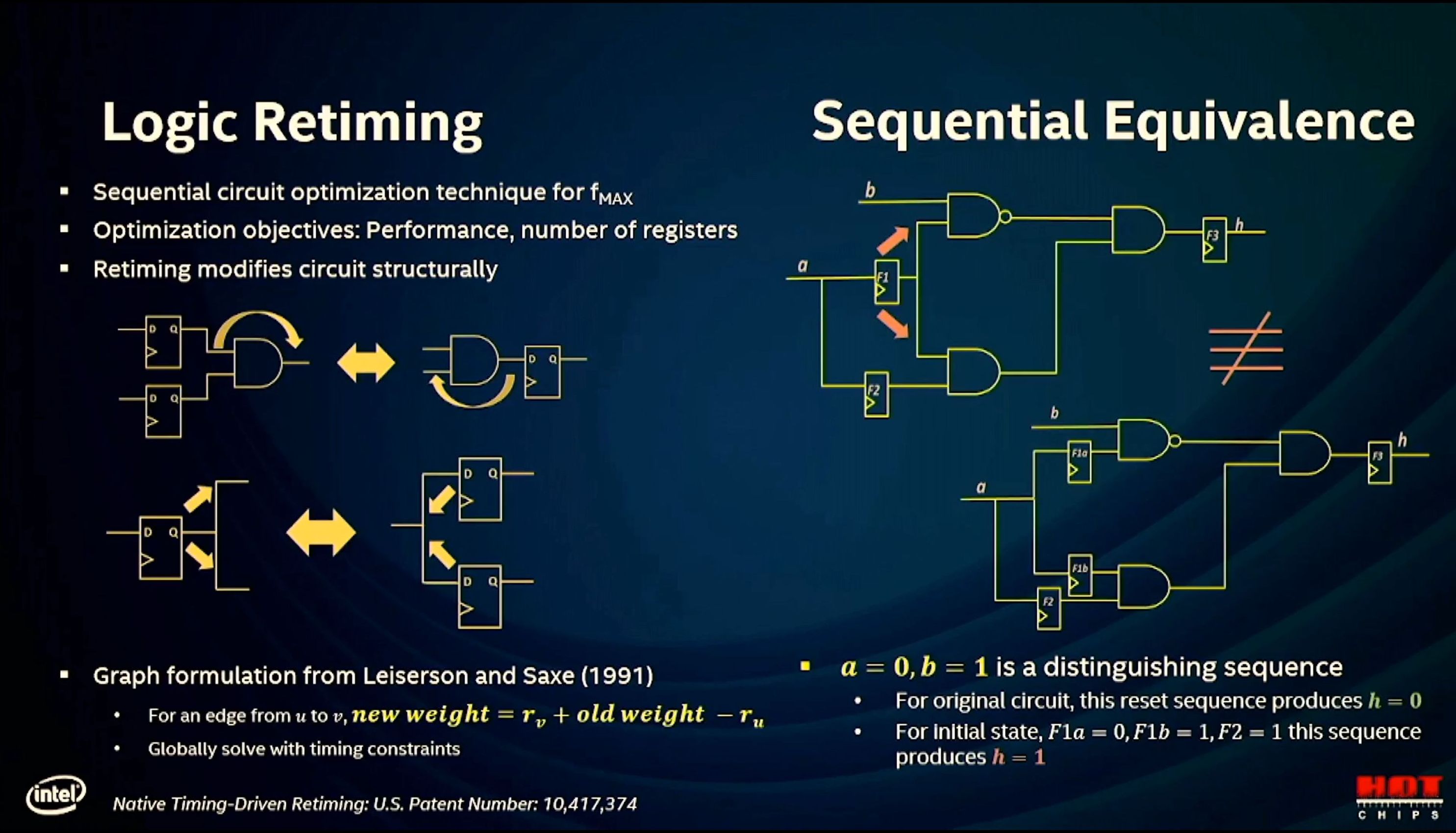
11:52AM EDT - This is a bit over my head. Hope you're getting something out of this :)




11:55AM EDT - Fine grained clock timing of 3ns
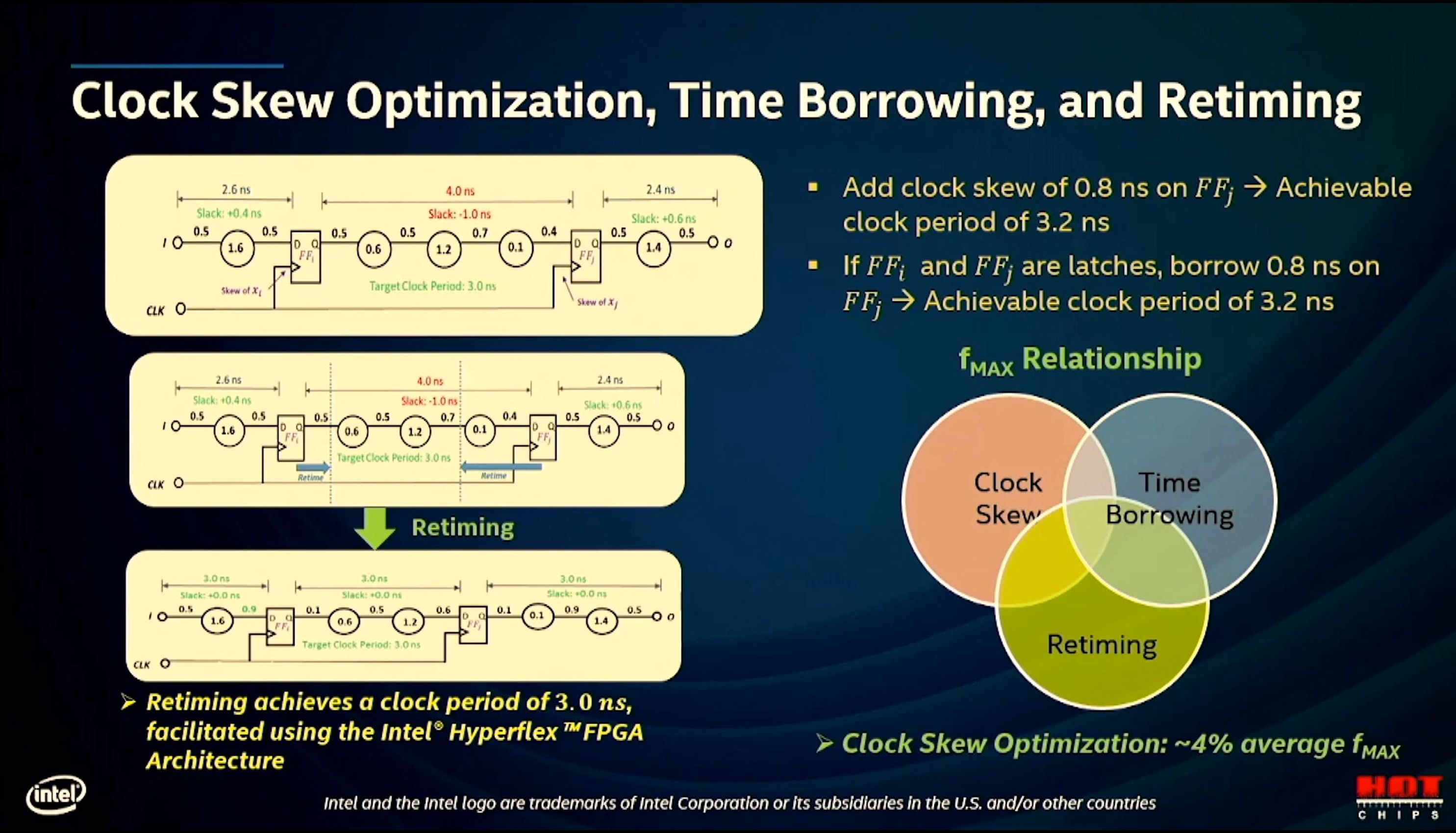
11:55AM EDT - Agilex has flexible clock skewing in the hardware, used by Quantus to help improve Fmax by 4% on average

11:56AM EDT - Different types of developers: low level or high level
11:56AM EDT - OneAPI offering is a compiler and toolchain for DC++ for direct programming as well as API programming
11:56AM EDT - Layered on top of the OpenCL offering which has Quartus Prime Pro as its base
11:57AM EDT - Q&A Time
11:58AM EDT - Q: What process? A: 10nm SuperFin with enhancements, such as metal stack. Subsequent products may leverage new enhancements
11:59AM EDT - Q: New plans to bring Xeon + FPGA in package? A: Nothing to disclose right now
12:00PM EDT - Q: EMIB now, Foveros coming? A: EMIB for tiles and HBM - some other experimental projects announced to create a chiplet ecosystem. Intel has many packaging technologies, so we look at many different opportunities but nothing to disclose right now.
12:00PM EDT - (Intel announced next-gen FPGA with Foveros at architecture day)
12:01PM EDT - Q: Register everywhere strategy from Stratix 10? A: We optimized hyperflex registers by reducing overall count while keeping Fmax abilities. We have enough so we can exploit them all. We also optimized it for setup-and-hold characteristics. We matured the algorithms in Quartus too.
12:02PM EDT - That's a wrap. Next up is Xilinx Versal, head on over to that live blog








8 Comments
View All Comments
JayNor - Tuesday, August 18, 2020 - link
It would be interesting to know if agilex FPGAs are being used in the Aurora project.It would also be interesting to know if eASIC migration can be done from 10nm agilex designs and, if so, what process they are using.
JayNor - Tuesday, August 18, 2020 - link
It would be interesting to know if oneAPI will provide some abstraction of tiled matrix processing that will be common between the new AMX CPU instructions and the XMX FPGA capabilities, as they have apparently made an attempt to do for SIMD operations.alfalfacat - Tuesday, August 18, 2020 - link
"FP19"I thought that was a typo, but no, that's really what it says on the slide. Any idea what format FP19 actually is? The only thing I could find on the internet is a roundabout description of Nvidia's new TF32 format being essentially a 19-bit floating point, but it would be good to get clarification on what they actually meant.
whatthe123 - Tuesday, August 18, 2020 - link
if it's anything like nvidia's TF32 its FP32 but with only 10-bit mantissa. So 1 + 8 + 10 = FP19 for AI workloads.tommythorn - Tuesday, August 18, 2020 - link
1+8+10 was confirmed offline.JayNor - Wednesday, August 19, 2020 - link
yeah, bfloat16 and tf32 ... Intel wants FPGAs as alternative backend for converted CUDA code in their oneAPI, so this is a good move by them to duplicate the tf32 data type.tommythorn - Tuesday, August 18, 2020 - link
This was probably the biggest surprise of the conference; Intel seems to have taken the lead of the fundamental innovation in logic and routing fabric whereas Xilinx seems content and focuses on adding hard blocks.The "register everywhere" concept was introduced with Stratix 10. In traditional FPGAs, the routing fabric is purely combinatorial: signals in arrive logically in the same clock cycle, which implies that long routes constrain the cycle time. Stratix 10 added bypassable-flops on all(?) routing which suggests you can retime using those. Rumors claimed that in practice Quartus had a hard time taking advantage of this and they sort of hint at this with an insistence of a complete revamping of the software. Very cool stuff. (I'm not affiliated in anyway with any FPGA company and holds no positions).
JayNor - Wednesday, August 19, 2020 - link
yeah, Intel used hyperflex-2 in agilex.https://blogs.intel.com/psg/2nd-generation-intel-h...